Brincando com JMH: microbenchmarking em Java
Ultimamente vi alguns “benchmarks” no LinkedIn sobre performance de coisas
específicas de Java, e eles argumentavem “nessa situação você precisa usar
isso”. Por exemplo, argumentaram que “para grandes volumes usar ArrayList
é melhor do que usar Streams na hora de gerar a nova coleção”.
Bem, não disponibilizaram o código do benchmark, então vamos escrever? Eles colocaram um por cima apenas do que seria feito:
final var prodsDTOcaros = prods.lista
.stream()
.filter(p -> p.getValor() > 100)
.map(p -> new ProdutoDTO(p.getId(), 1.1*p.getValor()))
.toList();
Ele queria a partir de uma lista de produtos, pegar os produtos com um
determinado valor (filter), mapear em um DTO (map) e juntar em uma nova
coleção.
Montando o benchmark
Primeiro ponto foi como desenhar pra fazer isso de maneira efetiva. A
tecnologia usada seria o JMH (Java Microbenchmark Harness). Para medir o
benchmarking de algo, anotamos um método com @Benchmark. Por exemplo:
package jeffque.bench;
import org.openjdk.jmh.annotations.*;
public class Exemplo {
@Benchmark
public void noop() {
// não faz nada
}
}
Isso vai fazer o benchmarking de… nada. Bem dizer, só isso mesmo. Agora, que
tal, só por exeprimentação, verificar o quão rápido se geram 1 milhão de
números em uma stream? Pra isso, vou medir o tempo do IntStream#range:
@Benchmark
public void gera_1_milhao() {
IntStream.range(0, 1_000_000);
}
Mas isso… streams do Hava são lazy. Isso não produz nada além do generator em si, que não trabalha. Vamos gerar os números? Que tal jogar em uma lista?
@Benchmark
public void gera_1_milhao() {
IntStream.range(0, 1_000_000)
.mapToObj(Integer::valueOf)
.toList();
}
Mas isso tem um problema. O objeto gerado não é usado. E talvez a hotspot detecte que isso é código inútil e remova isso, já que ele também não tem efeitos colaterais. Como podemos evitar isso?
Bem, usando o objeto! Vamos imprimir isso!
@Benchmark
public void gera_1_milhao() {
final var inteiros = IntStream.range(0, 1_000_000)
.mapToObj(Integer::valueOf)
.toList();
System.out.println(inteiros);
}
Mas… aí eu vou estar dependendo da velocidade do console. Isso não é uma boa,
ainda mais porque a stdout é uma saída bufferizada. Coisas estranhas não
desejadas vão entrar na medida na minha tentativa de usar o objeto. E isso eu
não quero.
Então… que tal engambelar o JIT? Se a gente retornar o valor, ele não saberá o que será feito do valor! Então vai precisar calcular!
@Benchmark
public List<Integer> gera_1_milhao() {
return IntStream.range(0, 1_000_000)
.mapToObj(Integer::valueOf)
.toList();
}
Agora o compilador nem o JIT vão saber que esse trecho gera um objeto que vai ser descartado.
Mas… a nível de desenho de benchmark, eu queria testar a geração dos números, e aqui eu estou adicionando um fator de confusão que é a coleta em uma lista. Então como fazer para não descartar esses valores? Não posso simplesmente imprimir na stdout os números, não posso coletar, mas ainda assim preciso passar para algum canto…
Aí entra o Blackhole!!! Ele suga tudo! Ele consome tudo que você entrega pra
ele!
// import org.openjdk.jmh.infra.Blackhole;
@Benchmark
public void gera_1_milhao(Blackhole blackhole) {
IntStream.range(0, 1_000_000)
.mapToObj(Integer::valueOf)
.forEach(blackhole::consume);
}
Cada cenário de teste aceita como parâmetro alguns valores especiais. O blackhole é um desses valores especiais.
Mas esse stream ainda tá fazendo uma coisa inútil… ele tá fazendo o boxing
do int em um Integer. Não preciso transformar para testar apenas a geração
dos números:
@Benchmark
public void gera_1_milhao(Blackhole blackhole) {
IntStream.range(0, 1_000_000)
.forEach(blackhole::consume);
}
Ok, agora eu apenas gero os números!
Vamos gerar mais cenários, começando em 1 e multiplicando por 10 até chegar em 1 milhão:
@Benchmark
public void gera_1(Blackhole blackhole) {
IntStream.range(0, 1)
.forEach(blackhole::consume);
}
@Benchmark
public void gera_10(Blackhole blackhole) {
IntStream.range(0, 10)
.forEach(blackhole::consume);
}
// ... que preguiça!
@Benchmark
public void gera_1_milhao(Blackhole blackhole) {
IntStream.range(0, 1_000_000)
.forEach(blackhole::consume);
}
Tá, não consegui… seria tão bom se o benchmark fosse… parametrizável…
Parametrizando
Outro valor especial que eu posso colocar em um método de benchmark é o objeto
de uma classe anotada como @State. E no @State eu posso anotar um campo
como @Parameter. Por exemplo:
package jeffque.bench;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
public class Exemplo {
@State(Scope.Benchmark)
public static class Input {
@Param({ "1", "10", "100", "1000", "10000", "100000", "1000000" })
public int size;
}
@Benchmark
public void geraInteiros(Input input, Blackhole blackhole) {
IntStream.range(0, input.size)
.forEach(blackhole::consume);
}
}
Agora, e se meu estado fosse derivado do parâmetro? Vamos mudar o que queremos
fazer de benchmarking, agora queremos iterar em strings de mais diversos
tamanhos. Para gerar a string, vou pegar o tamanho passado como parâmetro e
gerar a string como uma sequência de 1s:
@State(Scope.Benchmark)
public static class Input {
@Param({ "1", "10", "100", "1000", "10000", "100000", "1000000" })
public int size;
}
@Benchmark
public void iteraString(Input input, Blackhole blackhole) {
final var palavraUm = IntStream.range(0, input.size)
.mapToObj(i -> "1")
.collect(Collectors.joining());
palavraUm.chars().forEach(blackhole::consume);
}
Hmmm, aqui caímos no caso de que o benchmark está computando o tempo para gerar
a string também. Seria tão bom se no @State eu tivesse algo para fazer o
setup, né? E, bem! Existe isso sim! Existe a anotação de método @Setup que
permite exatamente isso!
Por exemplo, posso fazer com que o setup preencha a variável palavraUm dentro
do state, com o valor derivado dos parâmetros!
@State(Scope.Benchmark)
public static class Input {
@Param({ "1", "10", "100", "1000", "10000", "100000", "1000000" })
public int size;
public String palavraUm;
@Setup(Level.Trial)
public void criaPalavraComUm() {
palavraUm = IntStream.range(0, this.size)
.mapToObj(i -> "1")
.collect(Collectors.joining());
}
}
@Benchmark
public void iteraString(Input input, Blackhole blackhole) {
input.palavraUm.chars().forEach(blackhole::consume);
}
Agora sim, conseguimos medir o tempo para iterar em uma string, sem levar em conta o tempo para gerar o input do teste.
Múltiplos benchmarks
O mais divertido do benchmark é comparar diversas estratégias para o mesmo input. Então… que tal comparar quanto tempo eu consigo iterar na string?
Bem, na real, isso vai ser muito tempo… melhor seria levar em conta quantas operações ele consegue fazer em um segundo, né?
Vamos comparar, só a nível de curiosidade, iteração com o .chars (que gera
uma IntStream com os caracteres) e uma interação com .charAt(idx)?
@Benchmark
public void iteraString_chars(Input input, Blackhole blackhole) {
input.palavraUm.chars().forEach(blackhole::consume);
}
@Benchmark
public void iteraString_charAt_idx(Input input, Blackhole blackhole) {
final var len = input.palavraUm.length();
for (var i = 0; i < len; i++) {
blackhole.consume(input.palavraUm.charAt(i));
}
}
Hmmm, tecnicamente estou também fazendo um acesso de campo no objeto input a
cada iteração, junto ao blackhole.consume. Eu creio que isso vai ser
otimizado pela JVM? Sim, mas de toda sorte isso não é um teste justo. Eu
deveria melhorar antes. Então, vamos lá, melhorar esse cadinho:
@Benchmark
public void iteraString_chars(Input input, Blackhole blackhole) {
input.palavraUm.chars().forEach(blackhole::consume);
}
@Benchmark
public void iteraString_charAt_idx(Input input, Blackhole blackhole) {
final var palavraUm = input.palavraUm; // removi o acesso ao objeto no laço, boa!
final var len = palavraUm.length();
for (var i = 0; i < len; i++) {
blackhole.consume(palavraUm.charAt(i));
}
}
Ok, vamos anotar para pegar os resultados como operações por segundo, não por tempo médio da operação:
@BenchmarkMode(Mode.Throughput)
@Benchmark
public void iteraString_chars(Input input, Blackhole blackhole) {
input.palavraUm.chars().forEach(blackhole::consume);
}
@BenchmarkMode(Mode.Throughput)
@Benchmark
public void iteraString_charAt_idx(Input input, Blackhole blackhole) {
final var palavraUm = input.palavraUm; // removi o acesso ao objeto no laço, boa!
final var len = palavraUm.length();
for (var i = 0; i < len; i++) {
blackhole.consume(palavraUm.charAt(i));
}
}
Anotamos os benchmarks para pedir o throughput, o que me gera em operações por segundo. Esses operadores de configuração de rodar o benchmark pode ser colocado em nível de classe, então todos os métodos de benchmark são configurados para funcionar assim. Por exemplo:
@BenchmarkMode(Mode.Throughput)
public class Exemplo {
@State(Scope.Benchmark)
public static class Input {
@Param({ "1", "10", "100", "1000", "10000", "100000", "1000000" })
public int size;
public String palavraUm;
@Setup(Level.Trial)
public void criaPalavraComUm() {
palavraUm = IntStream.range(0, this.size)
.mapToObj(i -> "1")
.collect(Collectors.joining());
}
}
@Benchmark
public void iteraString_chars(Input input, Blackhole blackhole) {
input.palavraUm.chars().forEach(blackhole::consume);
}
@Benchmark
public void iteraString_charAt_idx(Input input, Blackhole blackhole) {
final var palavraUm = input.palavraUm; // removi o acesso ao objeto no laço, boa!
final var len = palavraUm.length();
for (var i = 0; i < len; i++) {
blackhole.consume(palavraUm.charAt(i));
}
}
}
Podemos rodar isso! O IntelliJ mostra um botãozinho especial para isso, então só clicar nele.
Quando eu clico para executar, a cada “teste” do benchmark, ele imnprime um cabeçalho. Por exemplo:
# JMH version: 1.37
# VM version: JDK 21.0.3, OpenJDK 64-Bit Server VM, 21.0.3+9-LTS
# VM invoker: [...]/.sdkman/candidates/java/21.0.3-tem/bin/java
# VM options: -Dvisualvm.id=48689543268083 -javaagent:/Applications/IntelliJ IDEA CE.app/Contents/lib/idea_rt.jar=63861 -Dfile.encoding=UTF-8 -Dsun.stdout.encoding=UTF-8 -Dsun.stderr.encoding=UTF-8
# Blackhole mode: compiler (auto-detected, use -Djmh.blackhole.autoDetect=false to disable)
# Warmup: 5 iterations, 10 s each
# Measurement: 5 iterations, 10 s each
# Timeout: 10 min per iteration
# Threads: 1 thread, will synchronize iterations
# Benchmark mode: Throughput, ops/time
# Benchmark: jeffque.bench.Exemplo.iteraString_charAt_idx
# Parameters: (size = 1)
Então ele mostra o resultado para as execuções:
# Run progress: 0.00% complete, ETA 01:56:40
# Fork: 1 of 5
# Warmup Iteration 1: 577549265.374 ops/s
# Warmup Iteration 2: 649866596.044 ops/s
# Warmup Iteration 3: 657863271.235 ops/s
# Warmup Iteration 4: 655966676.392 ops/s
# Warmup Iteration 5: 655758905.525 ops/s
Iteration 1: 659557535.280 ops/s
Iteration 2: 660348161.336 ops/s
Iteration 3: 656362946.337 ops/s
Iteration 4: 659781684.100 ops/s
Iteration 5: 648615347.537 ops/s
Aqui algumas coisas importantes…
- ele mostra o “run progress”, dá uma porcentagem do quanto ele já testou
- no “run progress” ele também dá uma estimativa de chegada, ETA
no meu caso, ele tá dizendo que ainda vai executar por pouco menos do que 2 horas - ele indica qual “fork” está sendo executado
- e finalmente ele mostra umas coisas chamadas de “warmup”
Então ele começa a imprimir as coisas que ele vai de fato começar a computar. Ele pega os resultados de cada iteração para computar o resultado final.
Funções de coisas no benchmark
O JMH dispara diversos processos para fazer a computação. Eles não rodam na mesma JVM, eles rodam em um processo separado, em um “fork”. O fork vai levantar um outro processo, com uma nova JVM, para rodar as coisas.
Um dos elementos importantes sobre o JMH rodar os testes em forks é porque assim você tem maior controle sobre as otimizações feitas pelo JIT. E isso impacta bastante! Assim, coisas de um teste de benchmark não vão gerar otimizações que vão impactar outro benchmark.
“Ah, mas como que vou fazer para que a JVM seja aquecida para executar os testes?” você pode se perguntar. Para isso que existe o “warmup”, aquecimento. Durante o aquecimento vão acontecer dois processos importantes:
- carga de classes pelo classloader, que é um processo de certo modo “lento” na primeira vez
- roda o JIT em trechos de códigos, o que permite que as coisas sejam executadas mais próximo de uma rodada real
Além disso, o JMH permite que você diga como você quer mensurar o seu
benchmark, através do @BenchmarkMode. Cabe aqui explorar o que faz mais
sentido para você. Por exemplo, na iteração por caracteres, o tempo médio era
tão rápido que não valia a pena tentar mensurar em segundos por operação.
Finalmente, o “estado” é a entrada do seu teste. Ele é de extrema importância
para testes parametrizados, em que você vai oferecer diferentes cargas para
testar um comportamento. O JMH não diz que o estado precise ser de uma
subclasse específica nem nada assim, apenas que seja uma classe anotada com
@State, definido um escopo, e se for necessário além dos valores
parametrizados também fornecer um @Setup.
Uma coisa importante sobre o teste é que a criação do estado não pode contar como tempo de operação, então o tempo que o JMH fica fazendo o setup do estado não entra nas estatísticas.
Outra coisa importante para evitar uma otimização que desafaça o código de teste é o blackhole, como citado anteriormente. Afinal, se uma função não tem efeitos colaterais e o seu objeto é prontamente desperdiçado, corre o risco do JIT arrancar a criação do objeto e não queremos isso. E também porque se você está em um processo de looping em que se criam diversos objetos, acumular eles em uma lista vai injetar o tempo de gerenciamento da lista como se fosse tempo de operação, poluindo assim o benchmark.
Falando em tempo… e se o processo descambar de modo maluco e não parar? Vai que injetamos uma falha no processamento e a coisa está em loop infinito?
Temos aqui o problema da parada na prática! Existem situações em que não dá para saber se um programa está trabalhando para chegar na solução do problema ou se ele está em um loop infinito que vai até o fim dos tempos. Existem situações triviais que detectamos quando um programa de fato está em loop infinito. Mas para isso… vou precisar que esse artigo seja consultado novamente: Uma demonstração de que Autômatos de Fila equivalem a Máquinas de Turing em poder computacional, parte 1.
Pegue uma máquina de Turing determinística. Ela tem o estado, a fita (memória) e uma posição de leitura/escrita. Se por acaso você estiver novamente no mesmo estado, com os mesmos símbolos na fita, na mesma posição de leitura, então você entrou em um loop trivial. E como seria isso em algo não teórico? Bem, o “estado” seria algo semelhante ao “program counter”, a instrução que está sendo executada. A cabeça de leitura teria algo como onde está mais ou menos a stack call? E finalmente a fita seriam os objetos em memória, com a posição na memória.
Detalhe que não vem ao caso explorar demais aqui, mas máquinas de Turing não-determinísticas tem o memso poder computacional do que uma máquina de Turing determinística, porém é mais trivial demonstrar/dar uma visão geral de algumas propriedades.
Ok, mas porquê perdemos esse tempo falando de computabilidade, autômatos e o problema da parada? Basicamente porque a única maneira segura para dizer que uma computação irá parar (em uma linguagem Turing Completa) é com um timeout. Para isso podemos indicar que o teste irá parar ao chegar nesse limite, por exemplo:
@Warmup(iterations = 2)
@Measurement(iterations = 5, time = 10, timeUnit = TimeUnit.SECONDS)
@Timeout(time = 500, timeUnit = TimeUnit.SECONDS)
@BenchmarkMode(Mode.Throughput)
public class Exemplo {
Aqui também coloquei algumas configurações sobre como vão ser feitar as medidas. Vão ser feitar 5 iterações (para cada fork), cada iteração vou chamar a função no benchmark diversas vezes por 10 unidades de tempo definidas como segundos.
Eventualmente a última computação sendo feita em uma iteração pode durar mais do que o tempo estipulado para fazer a repetição, mas se isso ocorrer o timeout impede que o Java fique estagnado para sempre.
Criando um bom estado
No exemplo acima, de gerar os dados para iterar, a informação criada foi bem trivial, só a lista de números incremental, ou uma string que só iria mudar o tamanho.
Mas as vezes isso não é satisfatório. Por exemplo, queremos verificar se o
filter é muito pior do que um if em um for ordinário. Para isso,
precisamos comparar “maçãs com maçãs”. Então precisamos necessariamente
comparar o mesmo conjunto de dados, então eles precisam ser gerados de maneira
garantidamente previsível, por mais que não se escrevam todos os objetos na
mão.
Então aqui entra a randomização! Mas não é apenas um new Random(), pois isso
não iria permitir ter o mesmo conjunto de dados obtido. Não, não… preciso
fornecer a mesma semente de randomização para gerar o mesmo conjunto de
informações pseudo-aleatórias.
Por exemplo, para verificar sobre a iteração de strings, para contar quantas
vezes o 1 aparece, posso gerar com a string com 1s ou espaços. Posso até
brincar com as proporções. Vamos resgatar o estado usado no exemplo anterior:
@State(Scope.Benchmark)
public static class Input {
@Param({ "1", "10", "100", "1000", "10000", "100000", "1000000" })
public int size;
public String palavraUm;
@Setup(Level.Trial)
public void criaPalavraComUm() {
palavraUm = IntStream.range(0, this.size)
.mapToObj(i -> "1")
.collect(Collectors.joining());
}
}
Agora vamos inserir uma aleatoriedade, 50% das vezes será 1 e os outros 50%
será espaço. Limitando a this.size. O Random tem o método
r.doubles(streamSize) que faz isso, mas poderia ser feito com
r.nextDouble() no meio do IntStream ou outras maneiras. Mas vamos com o que
parece ser mais idiomático:
@State(Scope.Benchmark)
public static class Input {
@Param({ "1", "10", "100", "1000", "10000", "100000", "1000000" })
public int size;
public String palavraUm;
@Setup(Level.Trial)
public void criaPalavraComUm() {
final var r = new Random();
palavraUm = r.doubles(this.size)
.mapToObj(p -> p < 0.5? "1": " ")
.collect(Collectors.joining());
}
}
Pronto. Mas isso não gera a mesma string pros testes: preciso fornecer uma
semente para o Random:
@State(Scope.Benchmark)
public static class Input {
@Param({ "1", "10", "100", "1000", "10000", "100000", "1000000" })
public int size;
public String palavraUm;
@Setup(Level.Trial)
public void criaPalavraComUm() {
final var r = new Random(15);
palavraUm = r.doubles(this.size)
.mapToObj(p -> p < 0.5? "1": " ")
.collect(Collectors.joining());
}
}
Pronto, agora temos uma geração de estados parcialmente aleatória porém
determinística dados os parâmetros. A ordem com o qual o Random será lido
pode sim influenciar o resultado, então é bom garantir que ele seja lido sempre
da mesma maneira na mesma ordem. Em outras palavras, se for gerar outro número
aleatório após o r.nextDouble() ou coisa assim, em uma stream do java 8,
basicamente saiba que você não tem controle de qual passo será necessariamente
executado e isso pode gerar uma bagunça no resultado final.
Para o caso em questão que abriu o artigo, sobre a lista de produtos, basicamente gerar os valores aleatoriamente em um único mapeamento de um índice para um objeto de produto em uma stream sequencial significa que tudo vai ser sempre gerado de maneira igual. Então eu fiz assim:
@State(Scope.Benchmark)
public class ListaProdutos {
public List<Produto> lista;
@Param({"1000", "10000", "1000000", "5000000"})
int size;
@Setup(Level.Trial)
public void criaEstado() {
final var r = new Random(15);
lista = IntStream.range(0, size)
.mapToObj(id -> new Produto(id, 256 * r.nextDouble()))
.toList();
}
}
O benchamrk do caso em questão
Algumas coisas estavam em voga:
- streams são lentas com grandes quantidades de objetos
- arraylists perdem pra linked lists ao inserir no final
E eu inseri um detalhe:
varé melhor do que mencionar umaArrayList<T>comoList<T>pois o bytecode gerado vai ser uminvokeVirtualde método deArrayListdo que uminvokeInterfacede umList
Com isso em mãos, vamos montar o cenário:
// estado
@State(Scope.Benchmark)
public class ListaProdutos {
public List<Produto> lista;
@Param({"1000", "10000", "1000000", "5000000"})
int size;
@Setup(Level.Trial)
public void criaEstado() {
final var r = new Random(15);
lista = IntStream.range(0, size)
.mapToObj(id -> new Produto(id, 256 * r.nextDouble()))
.toList();
}
}
// objeto base
public class Produto {
private final int id;
private final double valor;
public Produto(int id, double valor) {
this.id = id;
this.valor = valor;
}
public int getId() {
return id;
}
public double getValor() {
return valor;
}
}
// o record a ser obtido derivado do base
public record ProdutoDTO(int id, double valor) {
}
// teste com stream
@Benchmark
public List<ProdutoDTO> stream(ListaProdutos prods) {
final var prodsDTOcaros = prods.lista
.stream()
.filter(p -> p.getValor() > 100)
.map(p -> new ProdutoDTO(p.getId(), 1.1*p.getValor()))
.toList();
return prodsDTOcaros;
}
// teste com FOR, array list usando var
@Benchmark
public List<ProdutoDTO> oldForArrayList_var(ListaProdutos prods) {
final var prodsDTOcaros = new ArrayList<ProdutoDTO>();
for (final var p: prods.lista) {
if (p.getValor() > 100) {
prodsDTOcaros.add(new ProdutoDTO(p.getId(), 1.1*p.getValor()));
}
}
return prodsDTOcaros;
}
// outras variações...
// ...
public static void main(String[] args) throws Exception {
org.openjdk.jmh.Main.main(args);
}
Para configurar corretamente a dependência, puxei ela do Maven:
<properties>
<jmh.version>1.37</jmh.version>
</properties>
<dependencies>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
</dependency>
</dependencies>
<!-- adicionar o plugin para processamento de anotação -->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>21</source>
<target>21</target>
<annotationProcessorPaths>
<path>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
</build>
O main faz a magia de procurar por todos os benchmarks, não só os da classe
que o engloba.
Ao medir pela primeira vez, não tinha ainda colocado medição de 5M de
elementos, e percebi uma incongruência com o resultado esperado: LinkedList
estava dominando os resultados perante ArrayList para o maior valor (1 milhão
de elementos). Para se ter uma ideia:
| Benchmark | (size) | ops/s |
|---|---|---|
| StreamList.oldForArrayList_List | 1000000 | 61.227 |
| StreamList.oldForArrayList_var | 1000000 | 62.588 |
| StreamList.oldForLinkedList_List | 1000000 | 125.581 |
| StreamList.oldForLinkedList_var | 1000000 | 117.474 |
O dobro de operações! Isso não deveria estar certo! Então, vamos testar hipóteses?
Eu esperava que, sempre, as operações em ArrayList fossem mais eficientes.
Porém, eu sei que ao chegar em uma quantidade, o ArrayList vai sofrer uma
“expansão”, onde o array em que os objetos são depositados sofre uma
realocação, um processo de sistema em que uma maior quantidade contínua de
memória é reservada para aquele objeto.
E o 1 milhão pode estar perto desse limite. Então, um valor acima do 1 milhão (não necessariamente 10 milhões) pode aproveitar esse fato. Eu espero que a função de tempo de uso para após a alocação seja negligenciável, porém a cada intervalo tenha um salto como um “imposto” de realocação. Algo assim:
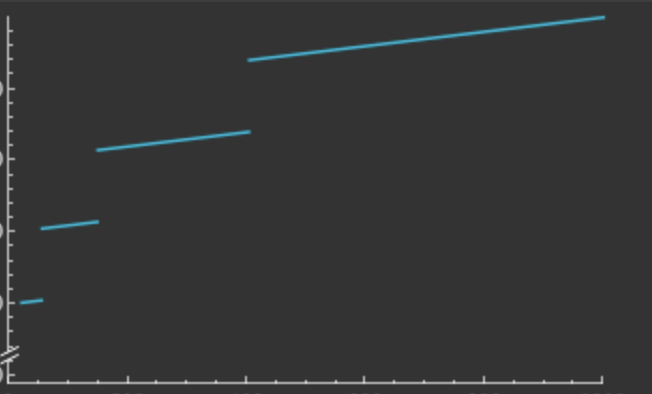
Gráfico plotado no WolframAlpha com o input
f(x) = 0.1* x + floor(log(x)) * 100, x in (0, 1000)
Então, preciso pegar algum valor entre esses saltos com aumentos
insignificantes o suficiente no ArrayList para que compensem o salto perante
o uso do LinkedList. Toda operação de LinkedList implica necessariamente a
criação de uma nova região de memória com o nodo, apontamento do antigo último
elemento para o novo elemento, apontar o novo elemento para o antigo último
elemento, fazer com que a estrutura que envelopa a lista ligada aponte para o
novo último elemento. São pelo menos 3 escritas em 3 regiões de memórias
distintas, em uma aplicação seria de se esperar que essas regiões de memória
estivessem em regiões bem separadas difíceis de se fazer um cache. Já para o
ArrayList as regiões a serem carregadas seriam no máximo duas (o do wrapper
com o ponteiro para a coleção e a região distante do array), e duas
atualizações apenas, sem necessitar normalmente de alocações extras.
Então com isso veio a ideia de tentar justamente os 5 milhões. E com 5 milhões, como foi o resultado?
| Benchmark | (size) | ops/s |
|---|---|---|
| StreamList.oldForArrayList_List | 5000000 | 10.964 |
| StreamList.oldForArrayList_var | 5000000 | 10.714 |
| StreamList.oldForLinkedList_List | 5000000 | 2.833 |
| StreamList.oldForLinkedList_var | 5000000 | 2.602 |
Ok, dentro do esperado.
Para conferir o projeto completo, basta conferir o repositório.
Um outro benchmark
Em um outro dia, vi outra postagem no LinkedIn falando sobre performance de
streams para fazer a soma de valores. O que essa postagem falava? Que fazer a
soma de uma lista de inteiros usando for era mais performático do que usando
IntStream.sum().
Parecia razoável? Sim. Eu concordava com a hipótese? Também. Então, vamos por
para teste. Após definir o estado (uma List<Integer>), primeiro teste que eu
fiz foi a não operação:
@Benchmark
public void noopForeach(Input i, Blackhole b) {
for (int l: i.lista) {
b.consume(l);
}
}
Nenhum resultado que acumule valores pode ser melhor do que esse. Essa função
faz o mínimo necessário para o trabalho acontecer: percorre todos os elementos
uma única vez. Como decidi que ia fazer soma de muitos valores, cerca de
algumas centenas de milhares a dezenas de milhões, resolvi acumular em um
long. Feita essa decisão, cabe aqui apenas escrever os testes. Umas pessoas
falaram que acessar pelo índice seria ainda melhor do que pelo for-each,
então botei isso a prova também:
@Benchmark
public long withForIndex(Input i) {
long result = 0;
for (int idx = 0; idx < i.lista.size(); idx++) {
result += i.lista.get(idx);
}
return result;
}
@Benchmark
public long withForeach(Input i) {
long result = 0;
for (int l: i.lista) {
result += l;
}
return result;
}
@Benchmark
public long withStream(Input i) {
return i.lista.stream().mapToInt(Integer::intValue).sum();
}
E o resultado que eu colhi foi:
| Benchmark | (size) | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|---|
| Summation.noopForeach | 100000 | thrpt | 15 | 24917.405 | ± 75.933 | ops/s |
| Summation.noopForeach | 50000000 | thrpt | 15 | 38.930 | ± 0.397 | ops/s |
| Summation.withForIndex | 100000 | thrpt | 15 | 15457.297 | ± 414.089 | ops/s |
| Summation.withForIndex | 50000000 | thrpt | 15 | 28.070 | ± 0.421 | ops/s |
| Summation.withForeach | 100000 | thrpt | 15 | 15472.856 | ± 196.674 | ops/s |
| Summation.withForeach | 50000000 | thrpt | 15 | 27.336 | ± 1.675 | ops/s |
| Summation.withStream | 100000 | thrpt | 15 | 19552.178 | ± 566.742 | ops/s |
| Summation.withStream | 50000000 | thrpt | 15 | 35.858 | ± 0.419 | ops/s |
Como esperado, a operação mais rápida foi a ausência de operação. Usando
ArrayList como estado, não foi significativo iterar via índice ou via
for-each, ambos trouxeram resultados muito próximos. Mas aqui a stream
surpreendeu, mantendo um nível alto de operações, tanto nos 100k quando nos 50
milhões.
O arquivo com esse benchmark específico está neste gist.