Publicando coisas da Computaria no Bluesky
Ok, Twitter foi bloqueado no Brasil. E Bluesky subiu em proeminência. O que fazemos? Nos adaptemos, claro.
Nota do período histórico: Esse artigo começou a ser escrito em 4/set/2024, durante o Grande êXodo. Reportagem sobre o assunto.
Bluesky fornece uma API bem rica e amigável para devs, então vou aproveitar para automatizar a publicação de material do Computaria nele. Por hora, vou deixar a automatização interna dentro do meu computador, mas em breve a intenção é subir e deixar disponibilizado para que o CI do Computaria dispare o serviço de mensageria.
Então, o que estamos fazendo aqui? Bem, o backbone da publicação, sem a burocracia maior de necessitar se preocupar no serviço.
Publicando mensagem via API
O primeiro ponto é: conseguir escrever uma mensagem. O Bluesky usa um protocolo de comunicação chamado de “at protocol”, e eles disponibilizam facilmente uma biblioteca para você poder trabalhar em cima com node.
O primeiro passo é se conectar através de um agent,
vide exemplo:
import { BskyAgent } from '@atproto/api';
import * as dotenv from 'dotenv';
import * as process from 'process';
dotenv.config();
// Create a Bluesky Agent
const agent = new BskyAgent({
service: 'https://bsky.social',
})
async function main() {
await agent.login({ identifier: process.env.BLUESKY_USERNAME!, password: process.env.BLUESKY_PASSWORD!})
await agent.post({
text: "🙂"
});
console.log("Just posted!")
}
main();
Ok, tudo bem, tudo certo, isso realmente funciona! Mas… botar a senha pessoal é meio estranho, né? Felizmente o Bluesky fornece uma alternativa, como aprendi lendo o post do André Noel do Vida de Programador: você pode criar uma chave privada para o bot. Não tenho o que falar mais ou de diferente do post acima, então não vou me delongar aqui.
Facets
Com essa montagem simples já conseguimos enviar textos simples. Mas eu estou aqui para enviar postagens, né? Então preciso subir o link do post e tratar preview do post.
Facet de link
Para publicar links, a documentação voltada para o tutorial nos fornece alguns passos, como usar “RichText” ou “markdown”, mas isso não é o modelo que eles utilizam nativamente:
import { RichText } from '@atproto/api'
// creating richtext
const rt = new RichText({
text: '✨ example mentioning @atproto.com to share the URL 👨❤️👨 https://en.wikipedia.org/wiki/CBOR.',
})
await rt.detectFacets(agent) // automatically detects mentions and links
const postRecord = {
$type: 'app.bsky.feed.post',
text: rt.text,
facets: rt.facets,
createdAt: new Date().toISOString(),
}
await agent.post(postRecord)
E se publica o texto em questão. Mas, note, ele tá pegando aqui “rich text” e desmembrando
em text e também facets. O que seria isso? Bem, ele tem uma documentação (inclusive
apontada de modo em destaque) sobre links e facets.
No caso de uma facet para linkar a um elemento externo. De modo geral, você coloca o texto
que deseja publicar e, no campo facets, você define um intervalo (em bytes, começo inclusivo
final exclusivo) do que vai ser aquele link. Por exemplo:
{
text: 'Urgente! 🚨: Streams paralelizadas em Java, o que acham disso?'
facets:[
{
index: {
byteStart: 15,
byteEnd: 44
},
features:[{
$type: 'app.bsky.richtext.facet#link',
uri: 'https://computaria.gitlab.io/blog/2023/02/27/parallel-stream'
}]
}
]
}
Vai publicar o texto:
Urgente! 🚨: Streams paralelizadas em Java, o que acham disso?
Nos bytes do intervalo [15,44) vai inserir uma facet do tipo link
($type: 'app.bsky.richtext.facet#link') apontando para a URI
https://computaria.gitlab.io/blog/2023/02/27/parallel-stream.
Existem outras factes, nominalmente menção e hashtag, mas para o caso específico só me importo com este, link.
Enriquecendo o card
Só o post com o link é muito pobre. Então, para chamar mais atenção, fui atrás de colocar um card. O card, para o que me compete, é composto de 4 campos (vide documentação):
- imagem
- título
- descrição
- URI
A URI é a exata mesma que vou usar na facet. A imagem (thumb) vai ser a foto da Baby, mascote do Computaria. Título e descrição vai ser completamente arbitrário.
Pegue aqui um exemplo de publicação: post no Bluesky.
Para esse exemplo, eu subi um blob com a Baby e linkei no objeto, usei como título Somando valores sem laços,
como descrição usei as tags da publicação javascript programação algoritmos e URI da
publicação.
Dado o texto e as facets que já vou usar, preciso colocar mais o campo embed no objeto
a ser publicado, para ficar mais ou menos assim:
{
text: "manja aqui o que escrevi: Somando valores sem laços",
facets: [...],
embed: {
$type: "app.bsky.embed.external",
external: {
uri: "https://computaria.gitlab.io/blog/2022/09/09/soma-valores-sem-loops",
title: "Somando valores sem laços",
description: "javascript programação algoritmos",
thumb: // blob
}
}
}
Subindo o blob
Bem, não tem muito segredo aqui. Você chama a função para fazer upload do blob:
let blob: Blob
// blob = ...
let contentType = "image/jpg"
let response: ComAtprotoRepoUploadBlob.Response =
await agent.uploadBlob(
blob,
{
encoding: contentType,
}
)
let thumbBlob: BlobRef = response.data.blob
Após fazer o upload do blob, ainda terei alguns momentos para publicar o que eu quero. Se eu não publicar, o Bluesky pode considerar aquilo um “dangling object” que pode ser coletado.
Agora, o mais interessante disso na verdade é que eu posso reutilizar o blob!
Serializando o blob com console.log e resgate manual
Minha primeira ideia foi pegar o objeto. Primeiro, testei dando um
console.log:
{
ref: CID(bafkreieg6lyhynujrhegdnvvh45pumpr24psnuhfk7gg2b4lm2x2aolf4q),
mimeType: 'image/jpeg',
size: 26533,
original: {
'$type': 'blob',
ref: CID(bafkreieg6lyhynujrhegdnvvh45pumpr24psnuhfk7gg2b4lm2x2aolf4q),
mimeType: 'image/jpeg',
size: 26533
}
}
Ok, e o que seria esse CID? Após pesquisar um pouco, vi que vinha desse
pacote multiformats/cid. Basicamente
é um padrão de identificador para sistemas distribuídos. O que importa para mim
é que o Bluesky usa.
Ok, posso salvar esse objeto em JS para resgatar depois, no caso passando o que
é CID para uma string, salvando portanto como:
{
ref: "CID(bafkreieg6lyhynujrhegdnvvh45pumpr24psnuhfk7gg2b4lm2x2aolf4q)",
mimeType: 'image/jpeg',
size: 26533,
original: {
'$type': 'blob',
ref: "CID(bafkreieg6lyhynujrhegdnvvh45pumpr24psnuhfk7gg2b4lm2x2aolf4q)",
mimeType: 'image/jpeg',
size: 26533
}
}
Ok, tudo tranquilo, mas vou precisar transformar os campos ref em objetos do
tipo CID afinal. E como faço isso?
No começo eu não tinha reparado muita coisa, não vi onde de fato eram usados
objetos do tipo CID, simplesmente assumi que poderia ser em qualquer lugar.
Isso significava que eu precisaria descer em todos os campos para desserializar
corretamente, para quando identificar um CID chamar o contrutor de objeto
CID corretamente.
Começamos com um objeto desconhecido. Então, vamos fazer uma introspecção fofa para saber mais detalhes dele mesmo. O primeiro caso é: e se for nulo? Bem, aqui retorno o próprio nulo:
// v: unknown
if (v == null) {
return null
}
E se for uma string? Bem, nesse caso eu preciso primeiro verificar se essa
string começa com CID(, porque se começar preciso proteger (e se não começar
devolvo verbatim):
// v: unknown
if (typeof v === 'string') {
if (v.startsWith("CID(")) {
return CID.parse(v.substring("CID(".length, v.length - 1))
}
return v
}
E se for um array? Bem, aí vamos normalizar cada objeto do array individualmente:
if (v instanceof Array) {
return v.map(normalizeCID)
}
Estamos acabando as possibilidades… e se for um objeto? Bem, nesse caso vou
precisar caminhar pelos campos individualmente. Vou pegar as Objects.entries
do objeto e normalizar cada entrada individualmente.
No começo, vamos começar com o objeto vazio, {}, pronto para colocar coisas
dentro. Como vou começar com ele, para cada nova entrada, vou expandir o meu
objeto acumulado e inserir a nova entrada normalizada:
// acc é o objeto de acumulação
// key é o nome do campo atual
// value é o valor do campo atual
const safeValue: any = normalizeCID(value)
return {
...acc,
[key]: safeValue
}
A redução como um todo fica:
// v: unknown
if (typeof v === 'object') {
return Object.entries(v).reduce((acc, [key, value]) => {
const safeValue: any = normalizeCID(value)
return {
...acc,
[key]: safeValue
}
}, {})
}
E, finalmente, e se v não for de nenhum desses tipos?
O tipo string é o único que precisa de tratamento direto para ser CID. O resto por incrível que pareça não precisa de lida direta, mas preciso verificar o conteúdo deles justamente por serem complexos. E os tipos complexos são objetos e arrays, ambos tratados já. Portanto, caso não encontre o tipo adequado, simplesmente devolve o valor direto porque ele não precisa ser protegido.
Ficou assim a função ao todo para resgatar o valor:
function normalizeCID(v: unknown): unknown {
if (v == null) {
return null
}
if (typeof v === 'string') {
if (v.startsWith("CID(")) {
return CID.parse(v.substring("CID(".length, v.length - 1))
}
return v
}
if (v instanceof Array) {
return v.map(normalizeCID)
}
if (typeof v === 'object') {
return Object.entries(v).reduce((acc, [key, value]) => {
const safeValue: any = normalizeCID(value)
return {
...acc,
[key]: safeValue
}
}, {})
}
return v
}
Com isso eu consigo montar novamente o objeto para enviar ele na função de postar conteúdo.
Deixando mais profissional o blob serializado
Aquilo que usei antes serviu para a primeira vez. Mas, e se eu quiser mudar a foto que uso de thumb? Como fazer?
A primeira coisa que fui atrás de fazer é como deixar de modo mais previsível o
que vai ser serializado. Então descobri o JSON.stringify. Só que ele fazia
uma lambança com o CID! No lugar de transformar a referência em
{
// ...
"ref": "CID(bafkreieg6lyhynujrhegdnvvh45pumpr24psnuhfk7gg2b4lm2x2aolf4q)",
}
transformou em
{
// ...
"ref": {
"$link":"bafkreieg6lyhynujrhegdnvvh45pumpr24psnuhfk7gg2b4lm2x2aolf4q"
},
}
Pois bem, como resolver isso? Até porque preciso devolver o objeto pra ser um
CID, né? Basicamente transformando o objeto em uma versão cuja referência não
é um CID mas sim uma string! Eu vou pegar um BlobRef e transformar em algo
cuja referência foi stringificada. Vou chamar de BlobRefStringfied! Mas, como
seria ele?
Para o que me interessa, ele tem 4 campos:
type BlobRefStringfied = {
ref: string,
mimeType: string,
size: number,
original: // calma, calabreso, vamos chegar aqui...
}
Onde ref é a representação em string do que era o ref: CID em BlobRef. E
o original? Pela definição do tipo BlobRef, ele tem um campo original
também, que é um JsonBlobRef. Por sua vez, JsonBlobRef é um union type
de UntypedJsonBlobRef com TypedJsonBlobRef:
type UntypedJsonBlobRef = {
mimeType: string;
cid: string;
}
type TypedJsonBlobRef = {
$type: "blob";
ref: CID;
mimeType: string;
size: number;
}
type JsonBlobRef = UntypedJsonBlobRef | TypedJsonBlobRef
Arrá! É uma tagged union! Eu consigo saber qual o tipo específico se olhar para
o campo $type!
function isTypedJsonBlobRef(blob: JsonBlobRef): blob is TypedJsonBlobRef {
return (blob as any)["$type"] != null
}
E com isso me preocupar com proteger apenas no caso em que for de fato um
TypedJsonBlobRef. Eu posso dizer então que BlobRefStringfied.original tem
como tipo uma união entre UntypedJsonBlobRef e um tipo parecido com
TypedJsonBlobRef, porém removendo o ref: CID e adicionando um
ref: string. Posso declarar tudo na mão, ou…
Usar o tipo Omit do TS. Assim, posso pegar o TypedJsonBlobRef e derivar um
novo tipo sem esse campo ref: Omit<TypedJsonBlobRef, "ref">. E para
expandir esse tipo obtido? Posso simplesmente fazer um tipo de interseção
passando {ref: string}:
type BlobRefStringfied = {
ref: string,
mimeType: string,
size: number,
original: (UntypedJsonBlobRef | Omit<TypedJsonBlobRef, "ref"> & { ref: string })
}
Certo, agora eu tenho o tipo bem definido, mas como que deixo protegido em
relação a objetos do tipo CID? Bem, o .toString() de um objeto CID
retorna o código dele, então posso fazer uma interpolação para lidar com isso:
// blob é o parâmetro
{
...blob.original,
ref: `CID(${blob.original.ref.toString()})`
}
Mas só posso fazer isso se for um TypedJsonBlobRef!
// blob é o parâmetro
const original: (UntypedJsonBlobRef | Omit<TypedJsonBlobRef, "ref"> & { ref: string }) = (isTypedJsonBlobRef(blob.original))? {
...blob.original,
ref: `CID(${blob.original.ref.toString()})`
}: {
...blob.original
}
O BlobRef é garantido ter o CID no campo ref, então posso simplesmente
sempre proteger ele:
function blobRefAsPlainObj(blob: BlobRef): BlobRefStringfied {
const original: (UntypedJsonBlobRef | Omit<TypedJsonBlobRef, "ref"> & { ref: string }) = (isTypedJsonBlobRef(blob.original))? {
...blob.original,
ref: `CID(${blob.original.ref.toString()})`
}: {
...blob.original
}
return {
ref: `CID(${blob.ref.toString()})`,
mimeType: blob.mimeType,
size: blob.size,
original
}
}
Com isso eu consigo serializar. E para desserializar e deixar de fato útil?
Uma das coisas que descobri é que o BlobRef tem umas funções que eu não
estava pensando antes. Devido a essas funções, precisei fazer umas gambiarras,
copiando código original do BlobRef pra tornar minimamente compatível com o
que estou criando na mão:
import { ipldToJson } from '@atproto/common-web';
// ...
return {
...valoresApenas,
ipld() {
return {
$type: 'blob',
ref: this.ref,
mimeType: this.mimeType,
size: this.size,
}
},
toJSON() {
return ipldToJson(this.ipld())
}
}
E… bem, funcionou, o TS não reclamou de tipo e o upload de fato funciona. Vamos adentrar agora como que determinei os valores?
Para começar, preciso ler de algum lugar os dados do meu cache. Então,
desserializar, e a desserialização posso assumir que será um objeto do tipo
BlobRefStringfied:
const buff = fs.readFileSync(fileName)
const json = JSON.parse(buff.toString()) as BlobRefStringfied
Show! Agora, preciso converter o ref dele para ser um objeto CID e também
do campo original, se for o caso. Para criar um objeto do tipo CID se usa
a função CID.parse(source: string).
Para detectar se o original é do tipo TypedJsonBlobRef, só verificar a
presença do campo $type:
function isTypedJsonBlobRefStringfied(blob: unknown): blob is Omit<TypedJsonBlobRef, "ref"> & {ref: string} {
return (blob as any)["$type"] != null
}
Então, para desserializar:
const buff = fs.readFileSync(fileName)
const json = JSON.parse(buff.toString()) as BlobRefStringfied
const original = isTypedJsonBlobRefStringfied(json.original) ? {
...json.original,
ref: CID.parse(removeCIDmarksFromString(json.original.ref))
}: {
...json.original
}
const jsonCidNormalized = {
...json,
ref: CID.parse(removeCIDmarksFromString(json.ref)),
original
}
return {
...jsonCidNormalized,
ipld() {
return {
$type: 'blob',
ref: this.ref,
mimeType: this.mimeType,
size: this.size,
}
},
toJSON() {
return ipldToJson(this.ipld())
}
}
Com isso eu consigo fazer a serialização e a desserialização, mas ainda preciso definir onde irei fazer o cache em si.
Para fazer o cache dos dados do upload, me baseei em duas coisas:
- um hash do conteúdo do blob
- o tamanho do blob (para segunda verificação)
Nominalmente, coloquei o hash como sendo um diretório dentro do cache e dentro
dele nomeei o arquivo com o tamanho do blob, .json no final. Para o caso
da foto da Baby usando o SHA1 como hash, o caminho resultante se tornou:
.
└── 605ded129cb96d330cbec848b39bc751783361e0
└── 265333.json
Para calcular o tamanho do blob não tem nenhum segredo, só chamar blob.size.
Agora, para calcular o hash eu primeiro precisei passar o blob para um vetor
de dados. Nominalmente o Uint8Array (literalmente um array de bytes) dá conta
desse recado.
O cálculo do hash a grosso modo funciona assim: você precisa iniciar a contagem da hash, então para cada novo array de informação novo você pede para o hash se atualizar. Finalmente, quando terminar tudo, você pode pedir para ele soltar uma string com o hash. Para mim, o mais indicado é obter o hexadecimal da digestão dos blocos até agora.
// const baby: blob
const babyAsArray = new Uint8Array(await baby.arrayBuffer())
const dig = crypto.createHash('sha1').update(babyAsArray).digest("hex")
Esses dois pontos me permitem verificar qual seria o cache para se usar. Ou seja, dado essas informações e o blob, consigo resgatar do cache ou, na ausência, enviar um novo blob e guardar o blob no cache!
Só falta uma única coisa… eu preciso ter o content-type para enviar
para o Bluesky. Então, que tal retornar isso quando pego os dados da thumb?
const { blob: baby, contentType } = await blobBaby();
const babyAsArray = new Uint8Array(await baby.arrayBuffer())
const dig = crypto.createHash('sha1').update(babyAsArray).digest("hex")
retrieveFromCacheOrUploadBlob({ digest: dig, size: babyAsArray.length}, baby, contentType, uploadBlob)
Aqui o uploadBlob é uma função que vai falar com o Bluesky, do tipo
(blob: Blob, contextType: string) => Promise<ComAtprotoRepoUploadBlob.Response>.
E isso é a única coisa que eu tenho aberta, portanto o único argumento
(já que o blob da thumb em si é inferido, e também o esquema de cache):
async function getBabyBlob(uploadBlob: (blob: Blob, contextType: string) => Promise<ComAtprotoRepoUploadBlob.Response>): Promise<BlobRef> {
const { blob: baby, contentType } = await blobBaby();
const babyAsArray = new Uint8Array(await baby.arrayBuffer())
const dig = crypto.createHash('sha1').update(babyAsArray).digest("hex")
return retrieveFromCacheOrUploadBlob({ digest: dig, size: babyAsArray.length}, baby, contentType, uploadBlob)
}
Eventualmente essa função vou precisar expor, então só por um export;
export async function getBabyBlob(uploadBlob: (blob: Blob, contextType: string) => Promise<ComAtprotoRepoUploadBlob.Response>): Promise<BlobRef> {
const { blob: baby, contentType } = await blobBaby();
const babyAsArray = new Uint8Array(await baby.arrayBuffer())
const dig = crypto.createHash('sha1').update(babyAsArray).digest("hex")
return retrieveFromCacheOrUploadBlob({ digest: dig, size: babyAsArray.length}, baby, contentType, uploadBlob)
}
E sabe o que eu percebi agora escrevendo este post? Que não preciso fazer com que
retrieveFromCacheOrUploadBlob saiba qual o contentType do recurso baixado e
que foi abstraído dele, precisa apenas saber fazer o upload. Assim, posso por
contentType na clausura da função que faz o upload:
export async function getBabyBlob(uploadBlob: (blob: Blob, contextType: string) => Promise<ComAtprotoRepoUploadBlob.Response>): Promise<BlobRef> {
const { blob: baby, contentType } = await blobBaby();
const babyAsArray = new Uint8Array(await baby.arrayBuffer())
const dig = crypto.createHash('sha1').update(babyAsArray).digest("hex")
return retrieveFromCacheOrUploadBlob({ digest: dig, size: babyAsArray.length}, baby, (blob) => uploadBlob(blob, contentType))
}
O que simplifica o como retrieveFromCacheOrUploadBlob lida com a questão. Também
posso abstrair o blob em si, já que não uso nenhuma informação dele, só preciso
fazer o upload:
export async function getBabyBlob(uploadBlob: (blob: Blob, contextType: string) => Promise<ComAtprotoRepoUploadBlob.Response>): Promise<BlobRef> {
const { blob: baby, contentType } = await blobBaby();
const babyAsArray = new Uint8Array(await baby.arrayBuffer())
const dig = crypto.createHash('sha1').update(babyAsArray).digest("hex")
return retrieveFromCacheOrUploadBlob({ digest: dig, size: babyAsArray.length}, () => uploadBlob(baby, contentType))
}
Sistema de publicação
Para publicar, preciso ter acesso a algumas poucas coisas. Nominalmente;
- link para o que quero publicar
- mensagem + facets de link
- título e descrição para o post
- o blob pra thumb
Vamos ver aqui o que realmente varia?
Bem, vamos supor que eu tenho acesso aos meus posts (e, advinha? Eu tenho, todo mundo tem, só clonar o repositório). Se eu conseguir mencionar o meu post de alguma maneira, eu consigo abrir ele em disco e extrair o título, extrair as tags para usar na descrição e até mesmo inferir a URI do post.
O blob? Bem, ele é fixo para mim. Então não é variável.
A mensagem propriamente dita também é variável. Os facets para colocar o link podemos trabalhar em cima de propriedades da própria mensagem, tipo a posição para inserir o link!
Urgente! 🚨: , o que acham disso?
^15
Onde 15 é a posição em bytes de onde começo a escrever. Então, pegando um título como o já mencionado “Streams paralelizadas em Java” (que tem 29 bytes de tamanho) temos aqui que a facet do link vai de 15 até 44.
Urgente! 🚨: Streams paralelizadas em Java, o que acham disso?
^ link vem daqui ^
até aqui (aberto) ^
https://computaria.gitlab.io/blog/2023/02/27/parallel-stream
E com isso eu consigo transformar em facets do post! Preciso ter a mensagem original, posição de inserção do link (parte da mensagem), texto de link e a URI com o destino (parte do post a ser publicado).
Então basicamente eu quero algo ({msg: string, positionInsertLink: number},
{title: string, uri: string}) => {msg: string, start: number, end: number,
uri: string}. Mas, bem, eu tenho equivalência em {title: string, uri:
string} com title: string => uri: string => {title: string, uri: string},
o que significa que eu posso ter uma função que receba a mesagem e o título
que retorne uma função que recebe a URI do link e deixa tudo povoado:
({msg: string, positionInsertLink: number}, title: string) => uri: string
=> {msg: string, start: number, end: number, uri: string}. E advinha
algo que bate com essa função? Um {msg: string, start: number, end: number}.
const textEncoder = new TextEncoder();
const textDecoder = new TextDecoder();
// ...
export function interpolateMessage(format: {msg: string, positionInsertLink: number}, text: string): {
msg: string,
start: number,
end: number
} {
const msgArr = textEncoder.encode(format.msg)
const leftFragment = textDecoder.decode(msgArr.slice(0, format.positionInsertLink))
const rightFragment = textDecoder.decode(msgArr.slice(format.positionInsertLink))
return {
msg: `${leftFragment}${text}${rightFragment}`,
start: format.positionInsertLink,
end: format.positionInsertLink + textEncoder.encode(text).length
}
}
Com isso agora para transformar em post só falta o link para transformar em facet. Mas podemos transformar isso em outra coisa também! Como, por exemplo, se eu quiser depurar posso retornar um HTML com a mensagem. Por exemplo:
Urgente! 🚨: , o que acham disso?
^15
Aí inserimos o texto e anotamos a posição de start e end:
Urgente! 🚨: Streams paralelizadas em Java, o que acham disso?
^ start ..... aqui (aberto) ^
Anotando o link:
Urgente! 🚨: Streams paralelizadas em Java, o que acham disso?
^ start ..... end (aberto) ^
https://computaria.gitlab.io/blog/2023/02/27/parallel-stream
E agora? Abrir o <a> no começo conforme a posição start e fechar com </a>
logo antes de indicada a posição end. Então isso viraria o seguinte:
Urgente! 🚨: <a href="https://computaria.gitlab.io/blog/2023/02/27/parallel-stream">Streams paralelizadas em Java</a>, o que acham disso?
Esse modelo HTML me foi bastante útil para depurar se a mensagem estava correta, se eu tinha percebido todos os acentos e caracteres multibytes para evitar criar uma mensagem engolindo uma letra, por exemplo. Como foi o caso do “🚨” que ocupava mais bytes do que caracteres.
A implementação dessa injeção de <a> no HTML eu fiz de modo bem remiescente
da injeção do título do post:
const textEncoder = new TextEncoder();
const textDecoder = new TextDecoder();
// ...
export function msg2html(msg: {
msg: string,
start: number,
end: number
}, href: string): string {
const msgArr = textEncoder.encode(msg.msg)
const leftFragment = textDecoder.decode(msgArr.slice(0, msg.start))
const atagText = textDecoder.decode(msgArr.slice(msg.start, msg.end))
const rightFragment = textDecoder.decode(msgArr.slice(msg.end))
return `${leftFragment}<a href=${href}>${atagText}</a>${rightFragment}`
}
Mas eu não preciso submeter o texto, posso deixar ele completamente aleatorizado. Assim:
export function message(): {
msg: string,
positionInsertLink: number
} {
const msgs: {msg: string, positionInsertLink:number}[] = ...
return msgs[/* algum número randômico */]
}
Alguns exemplos de msgs:
{
msg: "tava estudando uma coisinha... !",
positionInsertLink: 31
}
{
msg: "Urgente! 🚨: , o que acham disso?",
positionInsertLink: 15
}
Por hora estou mantendo esses valores hard-codados na aplicação, não houve necessidade de jogar isso em database nem nada.
Ok, agora preciso obter um número aleatório entre 0 e o tamanho da
quantidade de mensagens… Especificamente um inteiro em [0, msgs.length).
Entra aqui Math.random().
Essa função retorna algo no intervalo [0, 1). Se eu tenho algo nesse intervalo,
posso esticar esse intervalo por msgs.length que ficará em [0, msgs.length).
A distribuição de números nos dois casos ficará a mesma (considerando aqui
que a variável é perfeitamente contínua no intervalo, o que sabemos que não é,
mas é uma aproximação boa). Basicamente pegamos o valor aleatório, multiplicamos
por msgs.length e, então, truncamos a parte não inteira. O resultado será
um inteiro no intervalo [0, msgs.length):
export function message(): {
msg: string,
positionInsertLink: number
} {
const getRandomInt = (max: number) => Math.floor(Math.random() * max);
const msgs: {msg: string, positionInsertLink:number}[] = ...
return msgs[getRandomInt(msgs.length)]
}
Publicando via browser
Tendo o end-point que permite eu submeter a coisa, posso fazer um index.html para
permitir um mínimo de controle manual disso, né? Tipo, para quando eu quero compartilhar
um post antigo, por exemplo…
E se eu por essas informações em um <select>? Ok, fácil. Coloco para servir um index.html
estático, dou um parse nas informações do diretório de artigos publicados e faço um end-point
para resgatar essas informações e coloco no select. Ficando mais ou menos assim:
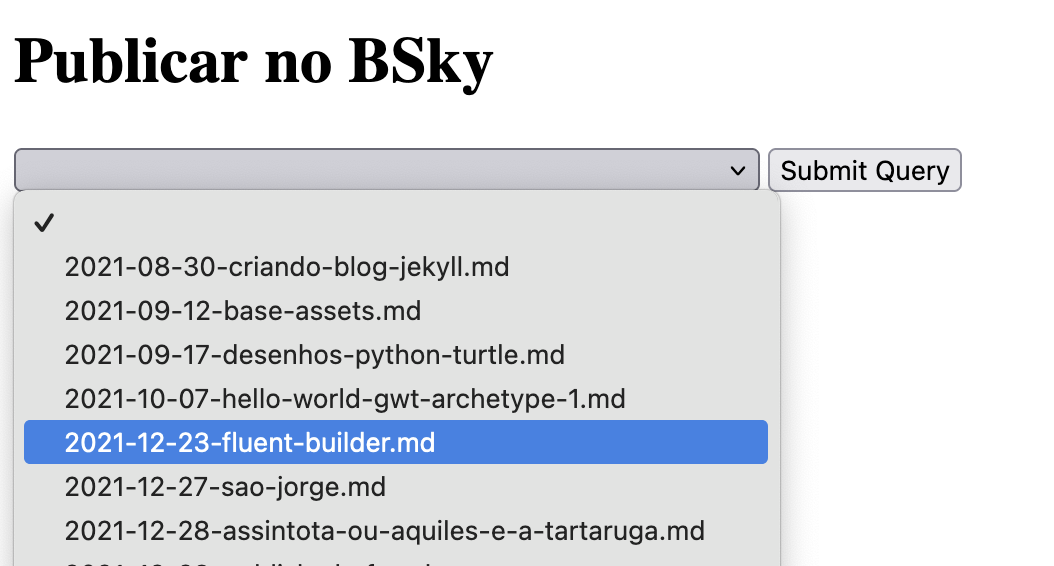
Com isso, consigo publicar? Consigo sim!
No select precisamos ter um dado que é a exibição para o humano e outro que é o valor a ser submetido como informação de formulário. Para mim, só o slug é o suficiente para identificar qual o post específico. Então posso pegar o slug do post apenas (como ele vai interpretar isso é questão do outro lado). Além disso, acho adequado colocar também uma opção em branco como a coisa “neutra” que usamos para começar.
Então, podemos por um end-point que retorna a lista de slugs. Depois de ter os slugs faço o quê?
Bem, vamos gerar um option a partir de um slug:
slug => {
const opt = document.createElement("option")
opt.value = slug
opt.text = slug
return opt
}
Beleza, parece razoável. E para ter a opção em branco logo no começo? Muito simples na real:
const opt = document.createElement("option")
E como juntar os dois? bem, simples:
const slugs = document.getElementById("slugs")
const computariaPosts = ...;
const opts = [document.createElement("option"), ...computariaPosts.map(slug => {
const opt = document.createElement("option")
opt.value = slug
opt.text = slug
return opt
})]
opts.forEach(element => {
slugs.add(element)
});
Certo, isso funcionou para dados hard-codados. E agora? Bem, vamos chamar a API.
O primeiro aspecto é: fetch é uma função assíncrona. E ela devolve uma resposta,
que por sua vez tem a leitura do corpo como algo também assíncrono. Fica algo assim
para fazer o recebimento dos dados:
const computariaPosts = await (await fetch("/api/slugs.ts")).json()
Tá, mas e o backend disso, como é? Na real bem simples:
import { VercelRequest, VercelResponse } from '@vercel/node';
import { getPostSlugs } from './computaria';
export default async function handler(request : VercelRequest, response: VercelResponse) {
response.json(getPostSlugs())
}
Nem o /api/computaria.ts em compensação oferece mais coisas interessantes…
basicamente o mais avançado lá foi apenas a carga do dotenv para garantir variáveis
de ambiente via arquivos .env. Além disso, uma simples chamada a uma API que o
próprio node disponibiliza:
import * as fs from 'fs'
import * as dotenv from 'dotenv'
dotenv.config();
const computariaDir = process.env.COMPUTARIA_POSTS!
export function getPostSlugs(): string[] {
return fs.readdirSync(computariaDir)
}
Um backend básico
Eu escolhi trabalhar com submissão de forms e Vercel, temos aqui que a vida é facilitada.
O conteúdo do formulário é todo preenchido em request.body. Por exemplo, ao submeter
o artigo Calculando o comprimento de um barbante num rolo, the hard
way, temos que o conteúdo do request.body
é:
{
"postSlug": "2022-11-17-comprimento-arco.md"
}
Como eu descobri isso? Fazendo um console.log(Objet.entries(request.body)). A função
Object.entries retorna um array de elementos. Cada elemento desse array contém apenas
duas posições: um nome e o valor associado a esse nome. Por exemplo, ao pedir as entradas
da requisição, ele imprime isso:
[ [ 'postSlug', '2022-11-17-comprimento-arco.md' ] ]
Com isso, eu posso pegar o slug do post e passar pelos processos naturais de processamento
e publicação fazendo um simples acesso direto: request.body.postSlug. Sabendo o slug eu
consigo o URI da publicação e também posso usar para pegar o título e uma espécie de
descrição do post (representado pelas taga envolvidas).
Como fazer isso? Bem simples! Basta pegar dentro da variável de ambiente COMPUTARIA_POSTS.
De lá eu navego para _posts/ e então coloco o slug no final para obter o caminho completo
do arquivo.
O processo de escrever as facetas, enriquecer com thumb já foi descrito, mas pra chegar lá precisamos de 3 informações da postagem:
- a URI
- o título
- uma descrição
E, olha só! Exatamente o que foi dito anterior que conseguimos pegar!
Então vamos pegar uma função que dado o slug pega essas informações? Uma espécie de
postSlug2PostInfo. Nesse caso, como vai ter leitura de arquivo, precisamos lidar
com esse caso como se fosse assíncrono. A entrada por vir uma simples string ou então
não existir, vir nula. A saída eventualmente vai ser URI, título e descrição. Logo,
essa função vai ter essa assinatura:
async function postSlug2PostInfo(postSlug: string | null): Promise<{
uri: string;
title: string;
description: string;
}>
Por uma questão de conveniência, se o postSlug passado for nulo eu retorno uma postagem
aleatória. Vamos primeiro explorar o mundo da postagem aleatória/quando o campo
tá em branco?
async function postSlug2PostInfo(postSlug: string | null): Promise<{
uri: string;
title: string;
description: string;
}> {
if (postSlug) {
// ...
}
return getRandomPost()
}
Certo, e como seria esse getRandomPost? Vamos limitar ao máximo o acesso
a disco. A solução é listar todos os arquivos do diretório de postagens e, para
o caso de ser selecionado, aí sim de fato ler o arquivo.
Vamos começar listando os arquivos. Para tal, usei
fs.readdirSync.
Daqui precisamos ter um jeito de ler o arquivo, algo assim:
fs.readdirSync(computariaDir)
.map(s => async () => (
// dá um jeito de ler a parada aqui
))
Eu preciso retornar 3 valores nessa API:
- URI (depende só do slug)
- Título
- “Descrição”
Aqui, a URI só necessita do slug:
function slug2postUri(s: string): string {
return `https://computaria.gitlab.io/blog/${s.substring(0,4)}/${s.substring(5,7)}/${s.substring(8,10)}/${s.substring(11, s.length - 3)}`
}
O formato das datas no slug está yyyy-MM-dd, já no blog ele muda para yyyy/MM/dd. E
finalmente faço a remoção da extensão do arquivo.
Para obter a descrição, preciso encontrar o campo tags dentro do frontmatter.
E para obter o título eu preciso encontrar o campo title dentro do
frontmatter. Portanto, preciso identificar o frontmatter propriamente dito, e
lidar com o seu começo e fim.
Graças aos poderes da padronização e da criação dos drafts através do
rake, eu sei que o meu
frontmatter terá exatamente três traços, ---. Então, que tal modelar a
leitura do frontmatter como uma máquina de estados?
Basicamente, eu tenho o estado inicial BEGIN, que, se encontrar a linha ---
vai para o estado FRONTMATTER. Caso contrário, BEGIN irá para o estado
POST e portanto não terá o que eu preciso de útil. Então eu continuo no
estado FRONTMATTER até encontrar uma nova linha ---, que aí indica o fim do
frontmatter e o começo propriamente dito do post, portanto justo que o estado
seja POST após achar esse valor.
Enquanto estou no estado FRONTMATTER, as linhas que começam com title: e
com tags: me interessam, pois vou trabalhar com elas.
Ao encontrar o título, faço uma pequena tratativa na linha, pra pegar tudo depois da primeira aspas até o final, ignorando a última aspas:
function extractTitle(s: string): string {
const start = s.indexOf('"')
return s.substring(start + 1, s.length - 1).replace(/\\"/g, '"')
}
No caso da descrição, eu só removo o nome do campo do começo mesmo, e aplico um
trim só pra não ficar sobrando espaço em branco a toa:
description = line.substring("tags:".length).trim()
E essa magia toda se dá ao fazer um line reading. Mas, como fazemos isso no
Node? Através do pacote padrão do Node readline. Eu posso pegar um stream de
dados e transformar em leitura de linha assim:
import * as readline from 'readline'
// ...
// abrir um arquivo chamado arquivo
const lineReader = readline.createInterface({ input: arquivo, crlfDelay: Infinity })
E com isso eu posso iterar (com await) em cima das linhas:
import * as readline from 'readline'
// ...
// abrir um arquivo chamado arquivo
const lineReader = readline.createInterface({ input: arquivo, crlfDelay: Infinity })
for await (const line of lineReader) {
// ...
}
Sempre bom lembrar de liberar os recursos (já que JS não tem
try-with-recourses que nem o Java nem defer como Go):
import * as readline from 'readline'
// ...
// abrir um arquivo chamado arquivo
const lineReader = readline.createInterface({ input: arquivo, crlfDelay: Infinity })
for await (const line of lineReader) {
// ...
}
lineReader.close()
A função inteira de extração dessas informações vdo frontmatter ficou assim:
export async function getPostInfo(postSlug: string): Promise<{
uri: string
title: string,
description: string
} | null> {
if (!fs.existsSync(computariaDir + postSlug)) {
return null
}
return {
uri: slug2postUri(postSlug),
...await titleDescription(computariaDir + postSlug)
}
}
async function titleDescription(post: string) : Promise<{ title: string, description: string }> {
let title = post
let description = post
const arquivo = fs.createReadStream(post)
const lineReader = readline.createInterface({ input: arquivo, crlfDelay: Infinity })
let state: "BEGIN" | "FRONTMATTER" | "POST" = "BEGIN"
for await (const line of lineReader) {
if (line === '---') {
if (state === 'BEGIN') {
state = 'FRONTMATTER'
continue;
}
if (state === 'FRONTMATTER') {
state = 'POST'
break;
}
}
if (state === 'BEGIN') {
state = 'POST'
break;
}
if (line.startsWith("title:")) {
title = extractTitle(line)
continue
}
if (line.startsWith("tags:")) {
description = line.substring("tags:".length).trim()
continue
}
}
lineReader.close()
arquivo.close()
return {
title,
description,
}
}
Trocando por HTMX
Ok, todo aquele script me pareceu desnecessário. E se usássemos HTMX?
HTMX vai permitir que eu carregue pedaços de HTML e injete em determinado lugar. No caso, quero
inserir dentro do select. Posso adaptar o script para me retornar já o HTML necessário para substituir
a construção das tags, eu aproveito a ideia de mapeamento já usada anteriormente. Só que como é
pura manipulação textual, não preciso me atentar a pedir document.createElement, posso simplesmente
criar.
A parte do lado do servidor ficou assim:
import { VercelRequest, VercelResponse } from '@vercel/node';
import { getPostSlugs } from './computaria';
export default async function handler(request : VercelRequest, response: VercelResponse) {
response.send("<option></option>" + getPostSlugs().map(slug => `<option value=${slug}>${slug}</option>`).join("\n"))
}
E o lado do front-end? Bem, para habilitar o HTMX na minha tela, preciso apenas
adicionar o script HTMX na aplicação. Segui
a documentação oficinal e coloquei o JS
da CDN dentro do <head> para baixar o script, junto a um checksum.
Basicamente não há mais motivos para existir nenhum script pessoal meu, já que originalmente eu estava usando apenas com o fim de refletir o estado do DOM de acordo com as respostas do servidor.
Para o HTMX funcionar, eu preciso anotar que o select vai pegar as informações do
end-point usando GET:
<select name="postSlug" hx-get="/api/slugs-htmx.ts"></select>
Só que o hx-get normalmente está associado a algum evento (como por exemplo submissão
do formulário, ou clique de um botão) óbvio disparado pelo usuário. Mas no meu caso
quero fazer ao carregar o documento. Posso fazer isso usando o hx-trigger="load":
<select name="postSlug" hx-trigger="load" hx-get="/api/slugs-htmx.ts"></select>
Bem, só isso já começou a ficar bacana… mas e se eu quiser recarregar os valores
do meu select? Bem, podemos criar um novo botão para fazer isso. E agora no botão
eu coloco como alvo o id antigo desse componente (o que significa retornar o id
dele). Ao todo, fica assim essa parte:
<select id="slugs" name="postSlug" hx-trigger="load" hx-get="/api/slugs-htmx.ts"></select>
<button hx-get="/api/slugs-htmx.ts" hx-target="#slugs" hx-swap="innerHTML">Reload slugs?</button>
Note que aqui o botão está indicando que o alvo para inserir as coisas via HTMX é
o #slugs, e que a ação que será tomada é substituir a parte de dentro da tag
(ht-swap="innerHTML") pela resposta do servidor. Agora eu consigo recarregar os
elementos do select sem parecer que é uma carga completa do servidor.
Ok, legal. E… e se eu não precisasse sair da tela? De jeito nenhum? Bem,
nesse caso o formulário precisaria bater usando HTMX. Preciso de um lugar
para depositar o conteúdo resgatado, então vou aproveitar e colocar um div
para tal.
Precisei resolver alguns menores conflitos com targets distintos para
a inserção das respostas do HTMX (nominalmente o do select assim que termina
o carregamento da tela); no final ficou assim:
<form hx-post="/api/" hx-target="#response" hx-swap="innerHTML">
<select id="slugs" name="postSlug" hx-trigger="load" hx-target="#slugs" hx-swap="innerHTML" hx-get="/api/slugs-htmx.ts"></select>
<button hx-get="/api/slugs-htmx.ts" hx-target="#slugs" hx-swap="innerHTML">Reload slugs?</button>
<input type="submit" />
</form>
<div id="response">Esperando...</div>
Cálculo do checksum
O HTMX em si já veio com o checksum. Mas… e se não tivesse vindo? Já peguei um caso em que uma extensão do HTMX não tinha o checksum, precisei calcular.
A maneira de integridade mais padrão que eu vi é usando o sha384. Ao menos foi essa a referência que achei. Então, como computar isso?
Uma alternativa é usando o https://www.srihash.org. Manda a URL do recurso que você quer e felicidade.
Outra alternativa seria localmente. Você precisa ter acesso ao arquivo. Por exemplo, via curl:
curl -sL https://unpkg.com/htmx.org@2.0.2
O -s é para o curl ser silencioso, não mostrar a velocidade de download e
tal, coisas que não são dados literais. o -L é porque o link pode gerar um
redirecionamento, e eu preciso lidar com isso. Eu poderia ter também o
htmx.js, mas por preguiça não o tenho.
Ok, tendo acesso ao arquivo, só mandar por uma pipeline bobinha que faz esse cálculo (extraído da referência da MDN):
curl -sL https://unpkg.com/htmx.org@2.0.2 | openssl dgst -sha384 -binary | openssl base64 -A
E quase pronto. Precisa por um sha384- na frente. E agora pronto.
Limitações
Por enquanto, o sistema não foi feito para ser completo nem complexo. Faltam questões essenciais para uma publicação web, como segurança. Mas, isso fica para depois.
Ele foi concebido por hora para funcionar como uma ferramenta auxiliar a o que eu tenho no computador. Além da questão da segurança que é determinada por variável de ambiente (assim eu controlo quando eu levanto a aplicação), falta também uma comunicação com o próprio blog. Estou trabalhando com extração de informações dos arquivos do repositório, quem sabe no futuro eu não adapte o próprio computaria para gerar um arquivo facilmente parseável para esse tipo de publicação?
Os fontes do envio para o Bluesky você encontra no repositório de envio de mensagens do computaria.