Quem é mais poderoso, uma Máquina de Turing com fita limitada ou um Autômato Finito?
Inspirada nesta resposta do Stack Overflow em portugês.
Temos uma máquina de Turing. Ela é definida como contendo uma fita infinita, vide Uma demonstração de que Autômatos de Fila equivalem a Máquinas de Turing em poder computacional, parte 1. Mas, eu posso limitar o poder dela, posso limitar o tamanho da fita dela.
Inclusive, para toda linguagem sensível ao contexto, é possível criar uma máquina de Turing capaz de reconhecê-la com uma fita de Turing limitada linearmente ao tamanho da entrada (ie, uma fita de tamanho proporcional ao da palavra sendo reconhecida). Vide LBA, CSL.
Assim sendo, como demonstrar que um autômato finito (determinístico ou não) é menos poderoso do que uma máquina de Turing cuja fita não possa crescer?
Note que aqui não é um autômato finito versus um LBA em geral, mas sim uma máquina de Turing com uma fita de tamanho fixado pela entrada! A versão mais restrita de um LBA!
Já foi explorado aqui no blog o conceito de autômato finito, nas postagens Expressões regulares podem detectar números primos? e O que é um autômato?. Recapitulando rapidamente: um autômato finito (determinístico ou não) lê a entrada e a cada símbolo lido altera seu estado. Se chegar no final da entrada em um estado de aceitação, então a palavra pertence a linguagem. Caso contrário, a palavra não pertence a linguagem.
Para autômatos finitos sem transições lambda, toda alteração de estado envolve necessariamente consumir um símbolo da entrada. Independente de ser um λ-NFA, um NFA ou um DFA, todos possuem o mesmo poder computacional (aka, conseguem reconhecer o mesmo conjunto de linguagens). Vamos hoje assumir isso como um fato, a demonstração fica para um momento futuro.
Ok, agora como podemos demonstrar que a máquina de Turing, mesmo com a fita finita, consegue ser mais poderoso, menos poderoso, ou reconhecer algumas linguagens que um DFA não reconhece e o DFA reconhece algumas linguagens que essa máquina de Turing não reconhece?
Para isso, vamos começar com uma máquina de Turing no estado q1:
q1
V
aaabbb
Se ela escrever a na casa de leitura, mover pra trás e ir para o estado q2,
vamos ter isso aqui:
q2
V
aaaabb
Podemos interpretar isso como uma função definida assim:
q1(b) ::= q2, a, <=
A primeira posição da tupla é o novo estado em que a máquina de Turing se
encontra, a segunda posição da tupla é o conteúdo que o cabeçote de escrita
escreve na fita e a terceira posição é o sentido que o cabeçote de leitura se
move. No caso, para a terceira posição, só podemos ter dois valores possíveis,
ou é => (direita) ou é <= (esquerda).
Certo, agora… vamos fazer umas limitações. A primeira é que não se pode ir além da entrada. Seria algo como:
qx
V
>aaabbb<
E as únicas transições aceitas para > (começo do input) ou para < (final do
input) seriam do tipo:
qx(>) ::= >, qy, =>
qz(<) ::= <, qw, <=
Se chegou na borda, volta pra fita (potencialmente em outro estado). Se não tiver transições com esse símbolo também é considerado válido. A priori, já que sabemos que esses símbolos existem, vou simplesmente omitir eles das próximas representações, deixar eles implícitos.
Ok, limitamos o input. Agora, definimos que começamos sempre da posição logo
após o começo da fita. No exemplo, para q0 o estado inicial, temos isso aqui:
q0
V
aaabbb
Com isso, temos o nosso autômato com a fita limitada do tamanho da entrada, sem direito a nem um gole de memória adicional.
Ok, até agora, tudo justo. E se eu limitar que eu sempre vou para a
direita? Isso é, toda operação necessariamente retorna => como terceiro
elemento da tupla. E, bem, já que o elemento jamais será lido novamente,
podemos simplesmente manter ele, né? Então, assim, com essa nova limitação,
todas as transições agora são do seguinte tipo:
qx(a) ::= a, qy, =>
Onde não há nenhuma relação sobre qx e qy. O que isso quer dizer? Bem, isso
quer dizer que esse conjunto de regras aqui é válido:
q0(b) ::= b, qb1, =>
qb1(b) ::= b, qb2, =>
qb2(b) ::= b, qb2, =>
qb2(a) ::= a, qa, =>
qa(b) ::= b, damnation, =>
q0(a) ::= a, q0, =>
qb1(a) ::= a, q0, =>
qa(a) ::= a, q0, =>
q0(c) ::= c, q0, =>
qb1(c) ::= c, q0, =>
qb2(c) ::= c, q0, =>
qa(c) ::= c, q0, =>
Se q0, qb1, qb2 e qa forem estados de aceitação, e damnation não for
estado de aceitação, então… bem, isso quer dizer estamos lidando com isso
aqui!
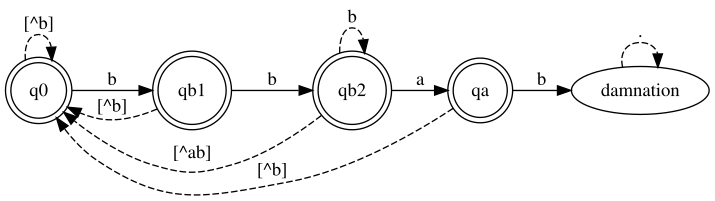
Basicamente um autômato finito que reconhece toda palavra que tem como alfabeto
{a, b, c} porém que não tenha a substring bbab.
Uma outra maneira de ler isso é transformar em transições gramaticais, onde cada estado se torna um não-terminal e toda transição que tem como produto um estado de aceitação se torna duas transições: uma com o estado (no caso de precisar ainda terminar de reconhecer a string) e outra sem o estado. Nesse exemplo, podemos escrever a seguinte BNF:
Q0 ::= b Qb1
Qb1 ::= b Qb2
Qb2 ::= b Qb2
Qb2 ::= a Qa
Qa ::= b Damnation
Q0 ::= a Q0
Qb1 ::= a Q0
Qa ::= a Q0
Q0 ::= c Q0
Qb1 ::= c Q0
Qb2 ::= c Q0
Qa ::= c Q0
Q0 ::= b
Qb1 ::= b
Qb2 ::= b
Qb2 ::= a
Q0 ::= a
Qb1 ::= a
Qa ::= a
Q0 ::= c
Qb1 ::= c
Qb2 ::= c
Qa ::= c
A produção
Qa ::= b Damnationpoderia ser omitida para indicar que não é aceita nessa gramática, mas o produto final é o mesmo já que para reconhecer não posso ter um não-terminal após as derivações da gramática. Mas o formalismo excessivo é para outro dia, aqui é formalismo em conta gotas.
Bem, como tivemos esse mapeamento para gramática generativa, podemos concluir de maneira inequívoca que de fato se trata de um autômato finito, é possível desenhar ele. Não garanto que ele seja sempre um autômato finito determinístico, como nesse exemplo bem desenhado acima, mas na pior das hipóteses vai ser um NFA.
Ok, posto isso, foi demonstrado que máquinas de Turing com fitas limitadas
reconhecem todas as linguagens que autômatos finitos. Agora, precisamos de um
caso de uma linguagem que seja possível reconhecer com uma máquina de Turing
com fita limitada mas que seja impossível reconhecer sem caminhar para a
esquerda. E, bem, tenho um fácil: uma string com a mesma quantidade de as e
de bs!
Como funciona? Bem, ela inicia no estado neutro. Estando no estado neutro, ao
ler um a ela entra em estado “procurando um b”, e vice-versa. Vou precisar
de um marcador especial de fita, chamado de x, que simplesmente indica que
aquele elemento da memória já foi lido. O x vai servir apenas para uma coisa:
permitir ignorar essa casa enquanto se procura o próximo elemento.
Ao entrar em modo “procurando um a”, vamos ignorar todo a encontrado e
passar pra frente, tal qual fazemos com x também. Ao encontrar um b,
substituímos esse b por x para indicar que esse símbolo já foi consumido,
mudamos o estado para retorno e andamos para a esquerda. Nesse estado
retorno vamos andando para a esquerda até achar um marcador y. Ao achar
esse marcador y, substitui ele por x e anda para a direita, agora de volta
ao estado neutro. Se chegou no final da string no estado neutro, reconhece a
linguagem!
Ah, esse y é colocar ao sair do estado neutro!
Vamos escrever aqui como seria essa linguagem:
q0(x) ::= x, q0, => # esse símbolo já foi usado, ignora
q0(a) ::= y, qb, => # estado "procurando b"
q0(b) ::= y, qa, => # estado "procurando a"
qa(a) ::= x, qR, <= # achou o "a", retornando
qb(b) ::= x, qR, <= # achou o "b", retornando
qa(x) ::= x, qa, => # esse símbolo já foi usado, ignora
qb(x) ::= x, qb, => # esse símbolo já foi usado, ignora
qa(b) ::= b, qa, => # não é o símbolo que procuro, ignora
qb(a) ::= a, qb, => # não é o símbolo que procuro, ignora
qR(a) ::= a, qR, <= # segue retornando!
qR(b) ::= b, qR, <= # segue retornando!
qR(y) ::= x, q0, => # achei o ponto marcado de início da busca
Como essa linguagem não pode ser reconhecida por um autômato finito, achei um exemplo de linguagem que a máquina de Turing, mesmo com a fita limitada, reconhece e que está fora da capacidade de reconhecimento dos autômatos finitos.
E, bem, essa demonstração de que essa linguagem não é possível ser reconhecida por um autômato finito fica para um outro post!
Indo um passo além
Até aqui eu demonstrei apenas a capacidade de reconhecer linguagens além das linguagens regulares. E escolhi um exemplo que acaba sendo equivalente a uma linguagem livre de contexto. Então, que tal ir além? E se eu conseguir demonstrar que é possível reconhecer linguagens que não são limitadas a linguagens livres de contexto? Isto é, que a máquina de Turing com a fita limitada reconhece coisas que seriam impossíveis para um autômato de pilha?
Bem, o exemplo mais clássico é: reconhecer uma palavra, em um alfabeto com 2 ou
mais letras, que aparece exatamente duas vezes. Algo como p p, para
p in {a, b}*.
Bem, aqui temos um caso bem bacana para resolver, porque agora, ao procurar por
um a, eu preciso simplesmente ter a opção de ignorar e ir em frente. Afinal,
essa palavra: abbaaabbaa está na linguagem, é a repetição da palavra abbaa.
Minha sugestão é trabalhar com uma parte não-determinística, a de fazer a
primeira marcação “aqui começa a outra palavra”, e depois tratar como
determinístico. Temos o estado neutro, que ainda está no não-determinismo, que
vai evoluir para um “procurando algum a não-deterministicamente” ou para
“procurando algum b não-deterministicamente”. A diferença é que, ao achar o
elemento que procura, ele vai ter três opções:
- chegar no final da leitura
- ignorar e continuar a busca não-determinística
- marcar aquilo com um
Wpara indicar o começo da palavra duplicada
Bem, se chegou no final da leitura sem encontrar nada… recusa a palavra…
Após marcar com W, ele vai voltar até a marca y. Após achar a marca y,
ele vai continuar a direita, e vamos ter duas opções aqui:
- acha um
W, indicando que “terminou” a primeira palavra - acha uma letra da entrada, então precisa procurar pela equivalente “do outro lado”
Para o caso de achar o W, isso significa que de fato encontramos algo com o
formato p p, mas não necessariamente apenas isso… Nessa situação, precisa
validar até o final de que só se lê símbolos usados. Se chegou no final e só
tem símbolos usados, então sim, é uma palavra formada pela concatenação da
palavra p com ela mesma (p p). Mas, se achar outra coisa, isso significa
que o que estamos lendo é algo na forma p p q, onde q in {a, b}*, |q| > 0,
e portanto está fora da nossa linguagem.
Ok, e no caso de achar uma letra? Agora vamos procurar por essa letra “do outro
lado”. Isso significa entrar em um estado que só vai indo para frente até
encontrar o W. E agora ele ignora símbolos usados até achar o que precisa. Se
achou algo que não foi um símbolo usado ou o símbolo que ele procura, então não
é uma palavra da forma p p, portanto recusa a palavra. Nessa situação, pode
até ser algo no formato qa g qb y, onde foi identificado que a subpalavra q
até apareceu aqui e lá, porém em algum momento onde era esperado encontrar um
a foi encontrado um b (aqui g e y são qualquer coisa, não foi
verificado), tudo isso com q, g, y in {a, b}*, |q| > 0.
Aqui, o estado inicial e o estado de equilíbrio na busca de resíduos são
estados de aceitação, todos os outros não. Vou criar um estado qQ só para
indicar que a entrada foi recusada explicitamente.
O estado inicial é q0, o estado de equilíbrio é q=. As buscas não
determinísticas vão ser qna e qnb, só para diferenciar de qa e qb,
botando esse n na frente para indicar o “não-determinismo”. Para avançar até
encontrar o separador W, vou indicar com os estados qwa e qwb. O estado
q~ indica a busca por resíduos.
q0(a) ::= y, qna, => # preciso achar uma subpalavra que começa com "a"
q0(b) ::= y, qnb, => # preciso achar uma subpalavra que começa com "b"
qna(a) ::= a, qna, => # ignorei esse "a", pego um próximo
qna(a) ::= W, qr, <= # vou considerar esse "a" em específico como começo da subpalavra
qnb(b) ::= b, qnb, => # ignorei esse "b", pego um próximo
qnb(b) ::= W, qr, <= # vou considerar esse "b" em específico como começo da subpalavra
qna(b) ::= b, qna, => # não procuro "b"
qnb(a) ::= a, qnb, => # não procuro "a"
qr(a) ::= a, qr, <= # estou retornando para a marcação
qr(b) ::= b, qr, <= # estou retornando para a marcação
qr(x) ::= x, qr, <= # estou retornando para a marcação
qr(W) ::= W, qr, <= # estou retornando para a marcação
qr(y) ::= x, q=, => # achei a marcação! estou em equilíbrio
q=(W) ::= W, q~, => # ok, acho que acabou, vamos procurar resíduos
q~(x) ::= x, q~, => # até agora tudo conforme esperado
q~(a) ::= a, qQ, => # puts, achei resíduo, recusando!
q~(b) ::= b, qQ, => # puts, achei resíduo, recusando!
q=(a) ::= y, qwa, => # preciso achar um "a" do outro lado!
q=(b) ::= y, qwb, => # preciso achar um "b" do outro lado!
qwa(a) ::= a, qwa, => # ainda não cheguei do outro lado...
qwa(b) ::= b, qwb, => # ainda não cheguei do outro lado...
qwa(W) ::= W, qa, => # cheguei do outro lado, a busca verdadeira começou!
qwa(W) ::= W, qb, => # cheguei do outro lado, a busca verdadeira começou!
qa(a) ::= x, qr, <= # achei o "a" que eu procurava, retornando
qb(b) ::= x, qr, <= # achei o "b" que eu procurava, retornando
qa(b) ::= b, qQ, => # achei algo errado! recusando!
qb(a) ::= a, qQ, => # achei algo errado! recusando!
qa(x) ::= x, qa, => # esse símbolo já foi usado, o que procuro está adiante...
qb(x) ::= x, qb, => # esse símbolo já foi usado, o que procuro está adiante...
Para reconhecer a palavra abbaaabbaa, seria mais ou menos assim (vou ignorar
as transições de estado que só estão indo pra lá ou pra cá sem rumo, e só vou
mostrar o caso que dá certo):
q0
V
abbaaabbaa
Consome o a e inicia a busca não-determinística de um a:
qna
V
ybbaaabbaa
Achou o a perfeito:
qna
V
ybbaaabbaa
Vamos voltar pro começo marcando o possível começo da subpalavra…
qr
V
ybbaaWbbaa
Ok, estamos em equilíbrio…
q=
V
xbbaaWbbaa
Encontramos um b…
qwb
V
xybaaWbbaa
Vou só mostrar aqui a transição para “o outro lado”:
qwb
V
xybaaWbbaa
E pronto, do outro lado! Podemos procurar um b:
qb
V
xybaaWbbaa
E voltamos…
qr
V
xybaaWxbaa
qr
V
xybaaWxbaa
q=
V
xxbaaWxbaa
qwb
V
xxyaaWxbaa
Como prometido, indo até o ponto que achou o que queria…
qb
V
xxyaaWxbaa
qr
V
xxyaaWxxaa
qr
V
xxyaaWxxaa
q=
V
xxxaaWxxaa
qwa
V
xxxyaWxxaa
Notou como ignorou os x?
qa
V
xxxyaWxxaa
qr
V
xxxyaWxxxa
qr
V
xxxyaWxxxa
q=
V
xxxxaWxxxa
qwa
V
xxxxyWxxxa
qa
V
xxxxyWxxxa
qr
V
xxxxyWxxxx
qr
V
xxxxyWxxxx
E, finalmente, o estado de equilíbrio…
q=
V
xxxxxWxxxx
Hora de buscar resíduos!!
q~
V
xxxxxWxxxx
E não achou nada de resíduo… portanto, palavra reconhecida!
q~
V
xxxxxWxxxx
Reconhecemos a ocorrência da palavra formada pela concatenação de uma palavra com ela mesma, coisa que não é possível fazer com um simples autômato de pilha. Portanto, máquinas de Turing, mesmo com fitas limitadas, conseguem reconhecer linguagens além das linguagens livres de contexto!
Notas sobre ser mais poderoso do que autômato de pilhas
Ok, demonstrei que a máquina de Turing, mesmo com a fita limitada, reconhece linguagens além das livres de contexto. Agora, vou dar uma noção de que mesmo esse modelo limitado de máquina de Turing é capaz de reconhecer todas as linguagens livres de contexto.
Para começar, vamos tomar como exemplo uma linguagem que produz palíndromos no
alfabeto {a, b}:
S ::= a S a
S ::= b S b
S ::= a a
S ::= b b
S ::= a
S ::= b
Pronto, só isso. Essa simples gramática gera todos os palíndromos possíveis no
alfabeto {a, b}. Agora, vamos usar como resultado que toda gramática livre de
contexto tem uma gramática “equivalente” (não no sentido esturtural, mas no
sentido de que gera a mesma linguagem, o mesmo conjunto de palavras) na forma
normal de Chomsky.
Resumindo fica assim:
S ::= A SA
SA ::= S A
S ::= B SB
SB ::= S B
S ::= A A
S ::= B B
S ::= a
S ::= b
A ::= a
B ::= b
Basicamente aqui vou aplicar um processo não-determinístico: como a produção de
um não-terminal para um terminal acontece sempre 1:1 na forma normal de
Chomsky, primeiro eu tento advinhar quais eram os não terminais que geraram
aquela palavra. Por exemplo, ababa, tem um caso que não deriva de S que é
A B A B A, e um caso que de fato deriva de S que é A B S B A. Em seguida,
vou percorrendo de alto a baixo procurando dois não terminais que eu sei que
vem de uma produção. Por exemplo, S B vem de SB. Ao achar um desses pares,
eu faço a substituição do segundo elemento pelo “elemento que produziu”, então
movo para a esquerda e transformo aquilo em uma espécie de “expurgo” X:
A B S B A viraria A B S SB A e em seguida A B X SB A. Com o expurgo
produzido, eu dou um jeito de mover o expurgo para o canto: A B SB A X. Após
mover ele para o canto, eu o ignoro e sigo achando as transformações adequadas.
Nesse caso aqui, seria B SB que se transforma em S. Fazendo a transformação
e ignorando o expurgo, tenho A S A. Então, S A percebo que é SA: A SA.
Então, A SA percebo que é S. Finalmente, cheguei no elemento inicial da
gramática, portanto essa palavra é válida.
Para fazer esse reconhecimento foram precisos muitos estados, mas não foi preciso escrever nada além dos limites da entrada. Portanto, toda gramática livre de contexto na forma normal de Chomsky é possível de se reconhecer sem necessitar usar memória além do input. E como toda linguagem livre de contexto possui necessariamente pelo menos uma gramática livre de contexto, e toda gramática livre de contexto pode ser transformada na forma normal de Chomsky, é seguro afirmar que essa máquina de Turing com fita limitada consegue reconhecer todas as linguagens livres de contexto.