Rodando o gitlab runner em um docker-in-docker
Estou fazendo um curso com foco em DevOps, e nesse curso foi necessário fazer uma pipeline de uma aplicação. Estava indo tudo bem, estava rodando diversas vezes os meus jobs nos GitLab Runners da instância GitLab.com.
Mas eu recebi o seguintes alerta:

E ainda nem estava na metade concluída do trabalho… Portanto, eu precisava de uma alternativa! E aqui entra o cadastro do runner do GitLab!
O que é o GitLab Runner
No GitLab, você define o seu próprio fluxo de CI. Basicamente ele é uma pipeline dividida em stages, sendo que cada stage é um agrupamento arbitrário com valor semântico.
Dentro de uma stage encontramos vários jobs. E é no job que determinamos que
algo será executado! Por exemplo, no post
Quebrei o CSS com a publicação anterior, e agora?,
foi criado o job alpine-test para que eu pudesse validar se era possível
retornar a funcionar a construção do Computaria usando como base uma imagem
alpine. E era um Runner quem iria pegar a descrição desse job e rodar!
Leia mais na documentação oficial.
Quando você hospeda seu código em uma instância do GitLab (como o GitLab SASS, também conhecido como gitlab.com), você pode optar por usar os runners disponibilizados nessa instância. No meu caso, eu optei por isso, pois era algo mais leve para manter e eu poderia publicar/corrigir um artigo a qualquer momento.
Os minutos a priori depende do seu plano ao usar o GitLab. No meu caso, eu estou rodando em cima do plano Free, o que me dá 400 minutos de pipeline (com opção de comprar mais minutos de computação).
Digo a priori porque existe o programa GitLab for Open Source, que oferece mais poder computacional. Mas esse não é o caso do Computaria.
Então, já que eu não posso rodar mais minutos nos Runners compartilhados da instância, eu precisei eu mesmo hospedar os meus Runners!
São os chamados “Self managed Runners”. Quem provê a instância do GitLab até controla a orquestração da pipeline, porém não executa o trabalho pesado de executar os jobs.
Para rodar o runner, você basicamente cadastra no seu grupo ou no projeto individual uma instância que deseja executar.
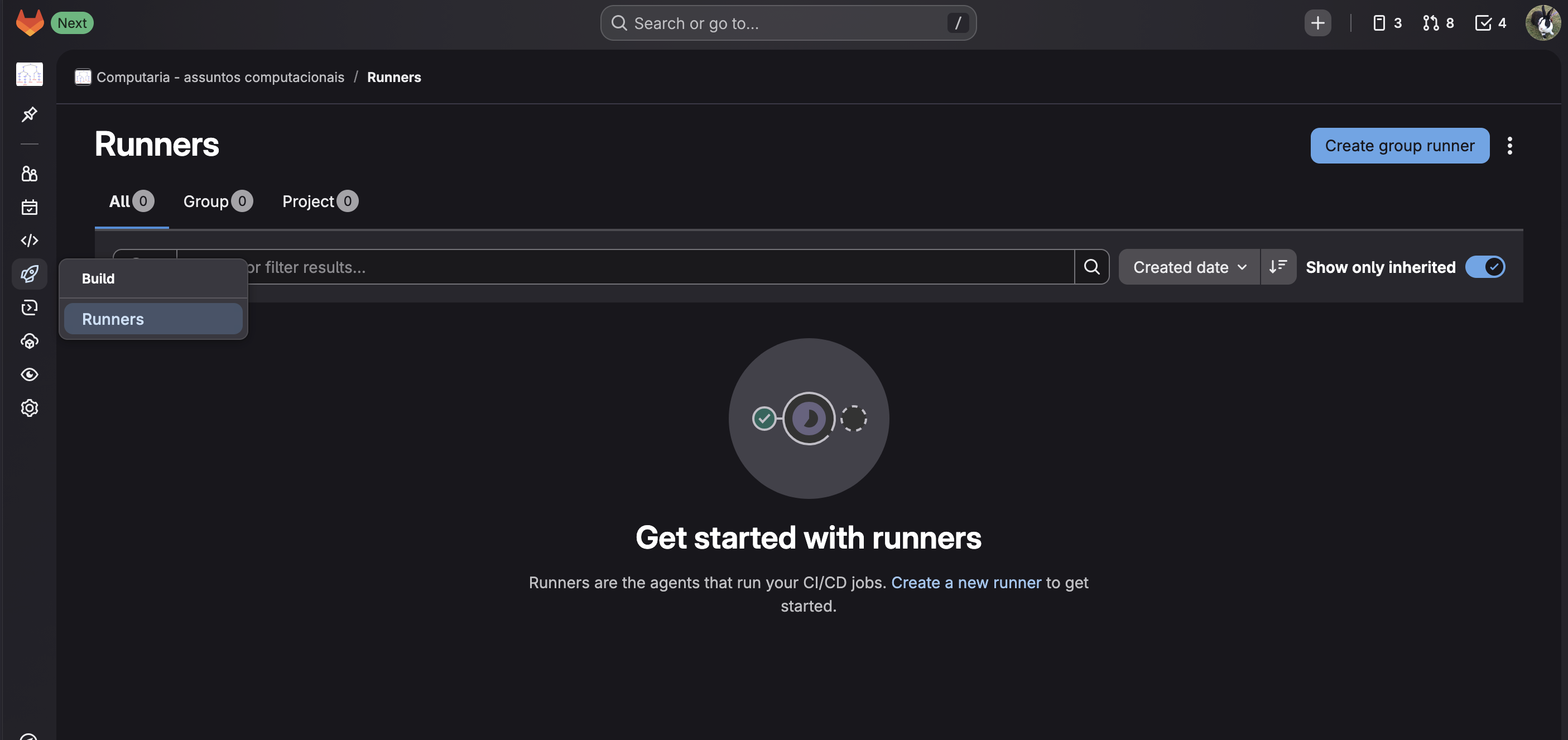
Para um grupo, você seleciona Build -> Runners e clica no botão
Create group runner:
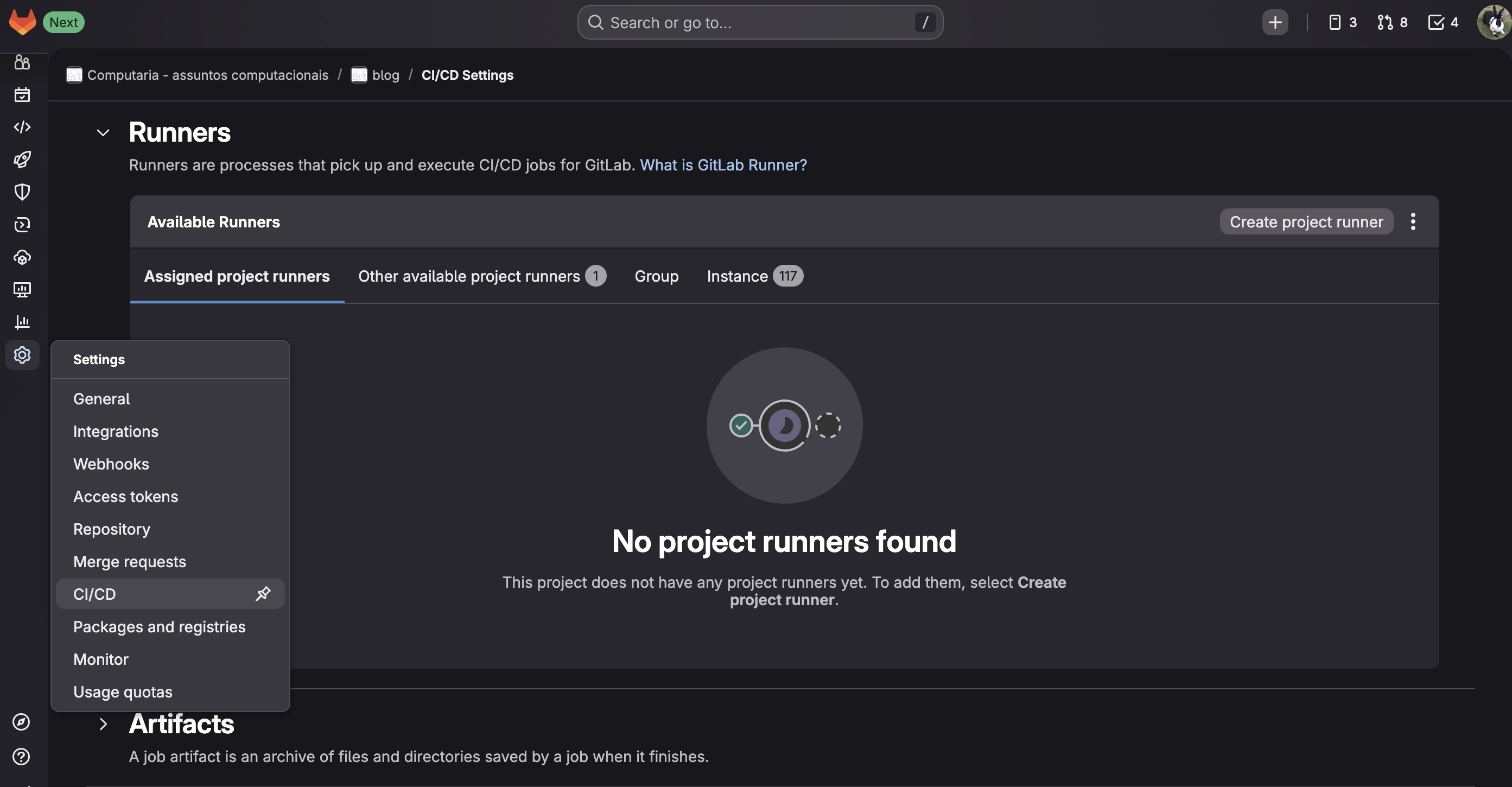
Para um projeto, você seleciona Settings -> CI/CD, abre a seção Runners e
clica no botão Create project runner:
Preencha algumas informações na primeira tela em relação a como o runner se comporta (executar untagged jobs, quais tags ele pode executar, outras coisas), e finalmente vai ter a tela que mostra os últimos passos para a execução do runner:
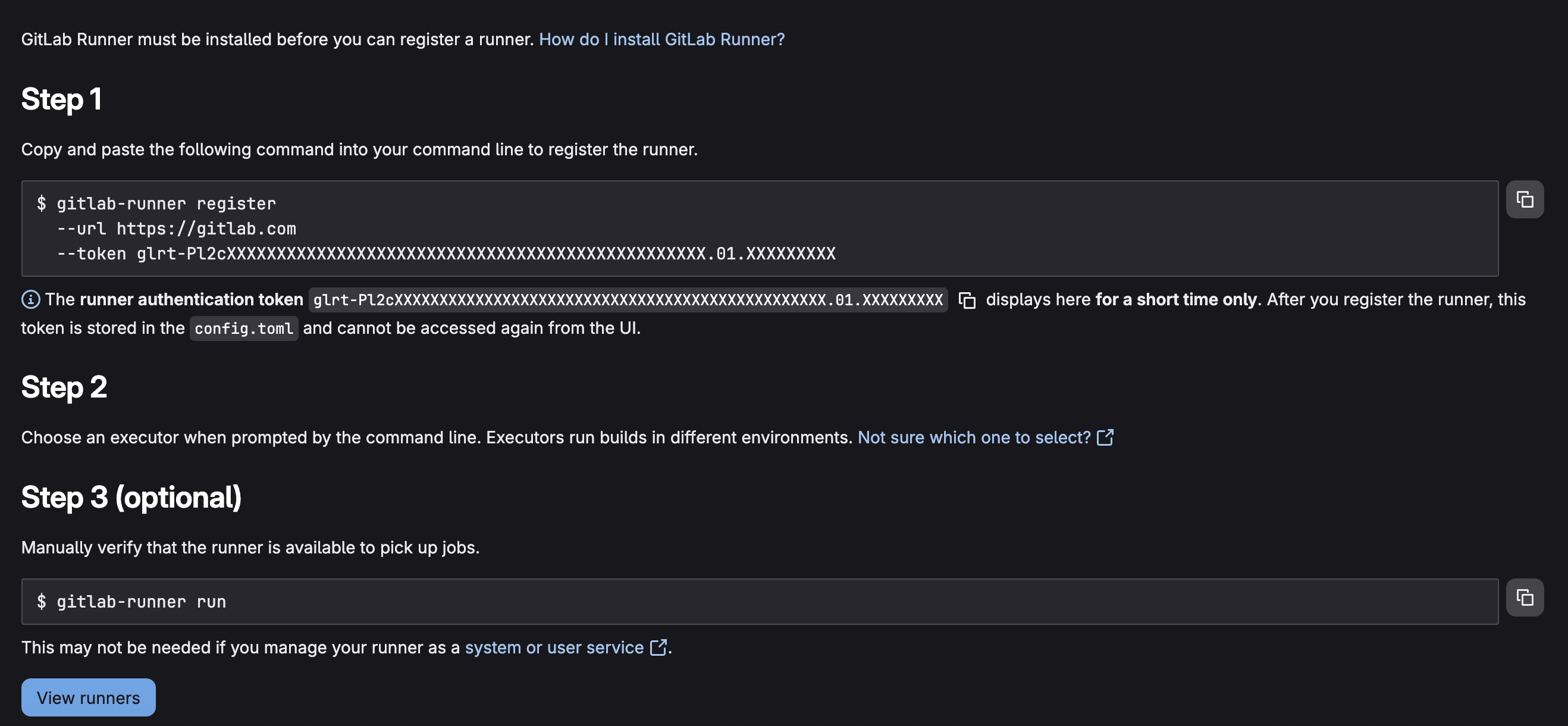
Salve o token, essa será bem dizer a sua última chance, após um curto período de tempo o token não estará mais disponível para visualização.
Então está na hora de resgatar esse token e cadastrar na sua instância local do GitLab Runner!
Entra o DIND
Devido a uma decisão arquitetural minha, não quero rodar o Runner diretamente
em cima do dockerd da minha máquina, mas sim dentro de um ambiente Docker
mais isolado: rodando o Docker no Docker. Em inglês, Docker in Docker, que dá
origem à nomenclatura DIND: Docker-IN-Docker.
Para rodar o DIND, você precisa executar o docker com privilégios. E, para
rodar os comandos no meu DIND, eu não posso rodar diretamente com o comando
docker. Se eu rodar docker run ..., ele será executado no meu dockerd,
não no dockerd do DIND. Então, tenho duas alternativas para isso:
- rodar um comando docker que roda um comendo docker no DIND
- expor a porta do DIND e, ao executar o comando
dockerlocalmente, garantir que a variável de ambienteDOCKER_HOSTaponta para o DIND
Vamos ver aqui como que faz? Bem, tem algumas maneiras para expor o dockerd
para o comando docker. As principais que eu conheço são:
- através de um socket unix
- através de uma conexão TCP segura (por padrão porta
2376) - através de uma conexão TCP INsegura (por padrão porta
2375)
Quando você roda o dind, a priori ele tenta expor uma conexão segura, mas
você consegue sobrescrever esse comportamento colocando a variável de ambiente
DOCKER_TLS_CERTDIR com uma string vazia. Assim, podemos subir o dind dessa
maneira:
docker run \
--rm \
-d \
--name="dind-test" \
-e "DOCKER_TLS_CERTDIR=" \
-p 2375:2375 \
--privileged \
docker:29-dind
Explicando cada ponto:
docker runestou pedindo para rodar algo via Docker--rmo container será removido quando ele parar, não ocupando espaço a toa--name="dind-test"criei um nome para o container para facilitar trabalhar com ele-e "DOCKER_TLS_CERTDIR="criando uma variável de ambiente chamadaDOCKER_TLS_CERTDIRcom conteúdo vazio-p 2375:2375estou expondo a porta2375, então bater emlocalhost:2375é encaminhado para esse container especificamente--privilegedpara rodar o DIND preciso de permissões com privilégiodocker:29-dinda imagem que estou usando
Dado isso, agora eu posso executar diretamente comandos docker nele, pois
estou expondo ele a conexões TCP:
DOCKER_HOST=tcp://localhost:2375 docker images
Ele retorna que agora não tem nenhuma imagem. De fato, é a primeira vez que
rodamos algo nele, não tem nada o que fazer. Podemos também executar algo nele
via docker exec:
docker exec -it dind-test docker images
Basicamente após falar que se deseja executar no container dind-test o
comando docker images. Podemos entrar na máquina também, na shell dela:
docker exec -it dind-test sh
E aqui podemos também pedir para ele executar os comandos adequados. Aqui é um
ambiente de shell, podemos rodar qualquer comando disponível de modo interativo
(inclusive o vi, que vem instalado por padrão).
Quando executamos diretamente no container, o comando docker segue o padrão
de tentar falar com um socket unix, já que localmente não tem definida a
variável DOCKER_HOST.
Caso você seja aventureiro (e eu precisei ser um dado momento do passado), você
ainda pode sobrescrever o comportamento padrão de entrada da imagem alterando o
ENTRYPOINT. Não precisa gerar uma imagem nova para isso, existe a opção de
alterar com a opção --entrypoint. Aqui, você informa como que o container vai
se iniciar, então o padrão de que a variável de ambiente DOCKER_TLS_CERTDIR
vazia não existe mais.
E por que alguém iria precisar fazer isso? Bem, tem algumas configurações que
são do próprio dockerd, e eu não encontrei maneira trivial de fazer elas
rodarem usando o entrypoint padrão do container. Por exemplo, posso configurar
para pegar de um registy próprio que usa conexão HTTP, com
--insecure-registry registry:5000, e assim eu posso também subir o meu
próprio docker-registry localmente e publicar imagens localmente.
Encapsulando no compose.yaml
No meu caso, não é de meu interesse compartilhar o meu DIND com o ambiente externo. Apenas manter ele para rodar os runners em cima. E no caso eu tenho também o interesse de rodar um comando mais complexo dentro do próprio DIND! Eu também tenho interesse de compartilhar um diretório do gitlab runner com o meu DIND para efeito de persistência. E, para ficar mais longevo que apenas o próprio DIND, compartilhar esse diretório de persistência com o mundo externo.
E assim, já que eu já vou compartilhar um diretório com o mundo externo, vou
colocar logo o meu script complexo dentro desse diretório. No caso, escolhi
um diretório chamado runner. Ele vai ter o script que faz a “magia” e, após o
registro do runner na instância do GitLab, mandar rodar a “magia” novamente
deixa o runner rodando feliz aceitando jobs.
services:
dind:
image: "docker:29-dind"
container_name: pipeline_dind
privileged: true
volumes:
- ./runner:/runner
E dentro dessa máquina, pipeline_dind, eu tenho a “magia”. No caso, escolhi
pela simplicidade uma interação bem simples:
- se não tiver o arquivo de configuração, faz o registro do gitlab runner
- se já tiver o arquivo de configuração, rodar em daemon o gitlab runner
#!/bin/sh
if [ -f /runner/config.toml ]; then
docker run --privileged --rm -d -v /runner:/etc/gitlab-runner/ -v /var/run/docker.sock:/var/run/docker.sock gitlab/gitlab-runner run
else
docker run --privileged --rm -ti -v /runner:/etc/gitlab-runner/ -v /var/run/docker.sock:/var/run/docker.sock gitlab/gitlab-runner register
sed -i 's/privileged = false/privileged = true/' /runner/config.toml
fi
Aqui eu estou compartilhando 2 coisas fundamentais com o gitlab-runner:
- o diretório
runner, que é onde vou salvar tanto o meu script de magia como o arquivo de configuração (poderia ser separado) - o socket unix do
dockerd
Após fazer o cadastro, em que informo o token, a URL da instância do gitlab, e
que o meu runner é do tipo docker, eu altero uma linha no toml: como eu
necessito rodar dind dentro do meu runner, eu preciso que o gitlab runner,
quando for subir algumas imagens docker, as suba com privilégios:
sed -i 's/privileged = false/privileged = true/' /runner/config.toml
Então faço essa substituição inline. Isso é para o meu caso em que eu rodo um
dind como serviço no .gitlab-ci.yaml, nem sempre isso é estritamente
necessário. O compose.toml fica exposto para se poder alterar, então é fácil
alterar ele manualmente (se você souber o que está fazendo, claro), e os
runners sabem como se recuperar após uma alteração no arquivo de configuração.
Podemos dizer que eles fazem um “self redeploy” automático e confiável a cada
alteração.
Na primeira vez que se executa a magia, o container é executado de modo
interativo: docker run -it [...]. Tomei essa escolha para que o usuário (no
caso, eu normalmente) pudesse customizar. Na segunda vez que roda a magia, já
vai ter o arquivo no lugar, então manda executar sem maiores encrencas o
gitlab runner como um daemon.
Para glorificar a preguiça obviamente eu criei um script só para executar a
magia dentro do DIND: run-magic-in-dind.sh:
#!/bin/sh
docker exec -it pipeline_dind /runner/magic.sh
Desafios não previstos
Devido a natureza o curso, um dos requisitos era rodar o
trivy para buscar vulnerabilidades conhecidas.
Encontrei uns templates pronto para isso, indicado pelo próprio site do
trivy
como parte do ecossistema:
Esses templates do SecObserve fazem tanto a análise do código estático, de suas dependências, quanto também da imagem. Para configurar esses jobs, usei o próprio esquema de templates do gitlab-ci:
include:
- "https://raw.githubusercontent.com/SecObserve/secobserve_actions_templates/main/templates/SCA/trivy_filesystem.yml"
- "https://raw.githubusercontent.com/SecObserve/secobserve_actions_templates/main/templates/SCA/trivy_image.yml"
Eu tinha a necessidade de salvar o registro da análise em uma pasta específica,
então precisei garantir a existência dela via before_script. Além disso, o
gitlab-ci agora permite que você suba o resultado específico da busca de
vulnerabilidades usando [job].artifacts.report.sast. Ficou assim o job do
trivy_filesystem:
trivy_filesystem:
extends: .trivy_filesystem
stage: security
before_script:
- mkdir -p reports/
variables:
TARGET: "package-lock.json"
REPORT_NAME: "reports/trivy_npm.json"
SO_UPLOAD: false
artifacts:
reports:
sast: "reports/trivy_npm.json"
paths: [ "reports/trivy_npm.json" ]
needs: []
rules:
- if: $CI_PIPELINE_SOURCE != "pipeline"
O
SO_UPLOADdeve ser marcado comotrue(padrão do template) se você estiver ativamente usando os serviços do SecObserve.
Isso funcionou bem. Mas a análise automática da vulnerabilidade cadastrada via
gitlab-ci no merge request
não está ativa para plano free.
Então, após rodar as análises, criei um outro job que simplesmente coleta as
informações e procura por falhas high (score 7.0) ou superior. Basicamente,
uma chamada a um arquivo JS:
vuln-scan:
image: node:25-alpine3.23
needs: [ "trivy_filesystem", "trivy_image" ]
stage: security
variables:
CSV_LIST_REPORTS_JSON: reports/trivy_npm.json,reports/trivy_image.json
script:
- node infra/vuln/check_vuln.js ${CSV_LIST_REPORTS_JSON}
rules:
- if: $CI_PIPELINE_SOURCE != "pipeline"
E aqui o script que checa as vulnerabilidades:
if (process.argv.length < 3) {
console.log("No JSON passed as args")
process.exit(0)
}
const accHighV = [];
for (const vulnFile of process.argv.slice(2).flatMap(csv => csv.split(',')).map(path => "../../" + path)) {
const sast = require(vulnFile);
const highV = sast.vulnerabilities.flatMap(vuln => vuln.ratings.map(r => [vuln,r])).filter(([v, rating]) => rating.score >= 7)
highV.map(([v,r]) => ({
id:v.id,
recommendation:v.recommendation,
description: v.description
}))
accHighV.push(...highV)
}
if (accHighV.length > 0) {
process.exitCode = 1;
console.error("Some high stakes vulnerabilities were found")
accHighV.forEach(([vuln, rating]) => {
let msg = `id: ${vuln.id} ${rating.severity} (${rating.score})
description: ${vuln.description}
recommendation? ${vuln.recommendation ?? "no recommendation =/"}
---
`;
console.error(msg)
})
}
E tudo estava funcionando maravilhosamente bem! Nos runners do gitlab.com! Porém… meus minutos acabaram, e com isso precisei rodar esse job localmente. Só que…
Pulling docker image ghcr.io/secobserve/secobserve-scanners:2026_01 ...
WARNING: Failed to pull image with policy "always": Error response from daemon: no matching manifest for linux/arm64/v8 in the manifest list entries: no match for platform in manifest: not found (manager.go:237:0s)
ERROR: Job failed: failed to pull image "ghcr.io/secobserve/secobserve-scanners:2026_01" with specified policies [always]: Error response from daemon: no matching manifest for linux/arm64/v8 in the manifest list entries: no match for platform in manifest: not found (manager.go:237:0s)
E, bem, precisava rodar a análise, né? Então, como contornar?
Por incrível que pareça é mais tranquilo do que eu pensei que seria! Basta
pedir para o gitlab-ci puxar uma imagem docker para uma plataforma específica.
Se ele não tinha o linux/arm64/v8, que tal rodar o job na mesma plataforma
que eram os runners compartilhados da instância? linux/amd64?
Para isso, precisei indicar na imagem que, ao subir com o docker, precisa estar adequada a plataforma:
trivy_filesystem:
extends: .trivy_filesystem
image:
name: ghcr.io/secobserve/secobserve-scanners:2026_01
docker:
platform: linux/amd64
# ... o resto segue igual
Há relatos (bem factíveis, por sinal) de que usar uma plataforma que não seja aquela em que o DIND está rodando ocasionava em uma execução bem mais lenta. Mas isso é só um scan de vulnerabilidades, eu aceito aumentar o tempo de execução de quase instantânea para alguns segundos.
E… bem, se isso estava acontecendo com o build de terceiros, o que fazer com o meu build? Com a minha? Vamos fazer multiplataforma!
Basicamente, para conseguir fazer o build usando como target múltiplas plataformas, segui alguns tutoriais para chegar nesse ponto:
first-docker-image:
needs:
- "unit-test-job"
image: docker:24.0.5-cli
services:
- name: docker:24.0.5-dind
alias: docker
stage: create-image
variables:
IMAGE_TAG_NAME: $CI_REGISTRY_IMAGE:temp-$CI_COMMIT_SHORT_SHA
PLATFORMS: linux/amd64,linux/arm64/v8
before_script:
- echo "$CI_REGISTRY_PASSWORD" | docker login $CI_REGISTRY -u $CI_REGISTRY_USER --password-stdin
script:
- touch .env
- docker buildx create --use
- docker buildx build --platform "$PLATFORMS" . -t "$IMAGE_TAG_NAME" --push
rules:
- if: $CI_PIPELINE_SOURCE != "pipeline"
O comando docker build --platform [PLATFORM] ... não aceitou usar como target
múltiplas plataformas alvo, então de fato precisei usar o
docker buildx build. Além disso, eu também não consegui enviar diretamente
via um simples docker push. Para gerenciar isso da maneira correta,
adiciona-se a flag --push no final do comando docker buildx build.
Além da opção de SAST, através do gitlab-ci podemos apontar para a cobertura de código nos testes e também para testes unitários:
unit-test-job:
image: node:25-alpine3.23
stage: test
before_script:
- npm ci
script:
- npm test -- --coverage --coverageDirectory=coverage
artifacts:
paths:
- coverage/
- reports/
when: always
reports:
coverage_report:
coverage_format: cobertura
path: coverage/cobertura-coverage.xml
junit: reports/*.xml
cache:
key: unit-test-job
paths:
- node_modules/
Uma das formas de saída da análise dos testes fica dentro de reports. No caso
específico, o JEST (ferramenta de teste para node usada no projeto) estava
configurado para emitir umas coisas bem interessantes:
/** @type {import('jest').Config} */
const config = {
verbose: true,
collectCoverage: true,
collectCoverageFrom: [
'src/**/*.js',
'!**/node_modules/**',
'!**/vendor/**',
],
coverageReporters: ["clover", "json", "json-summary", "lcov", "text", "cobertura"],
reporters: [
"default",
["jest-junit", {outputDirectory: 'reports', outputName: 'report.xml'}]
]
};
module.exports = config;
Para indicar para o gitlab-ci onde estará o resultado, usei de
[job].artifacts.junit. E além desse do teste junit, tem também a cobertura,
que já na versão gratuita o GitLab exibe no merge request quais linhas foram
cobertas e quais não foram:
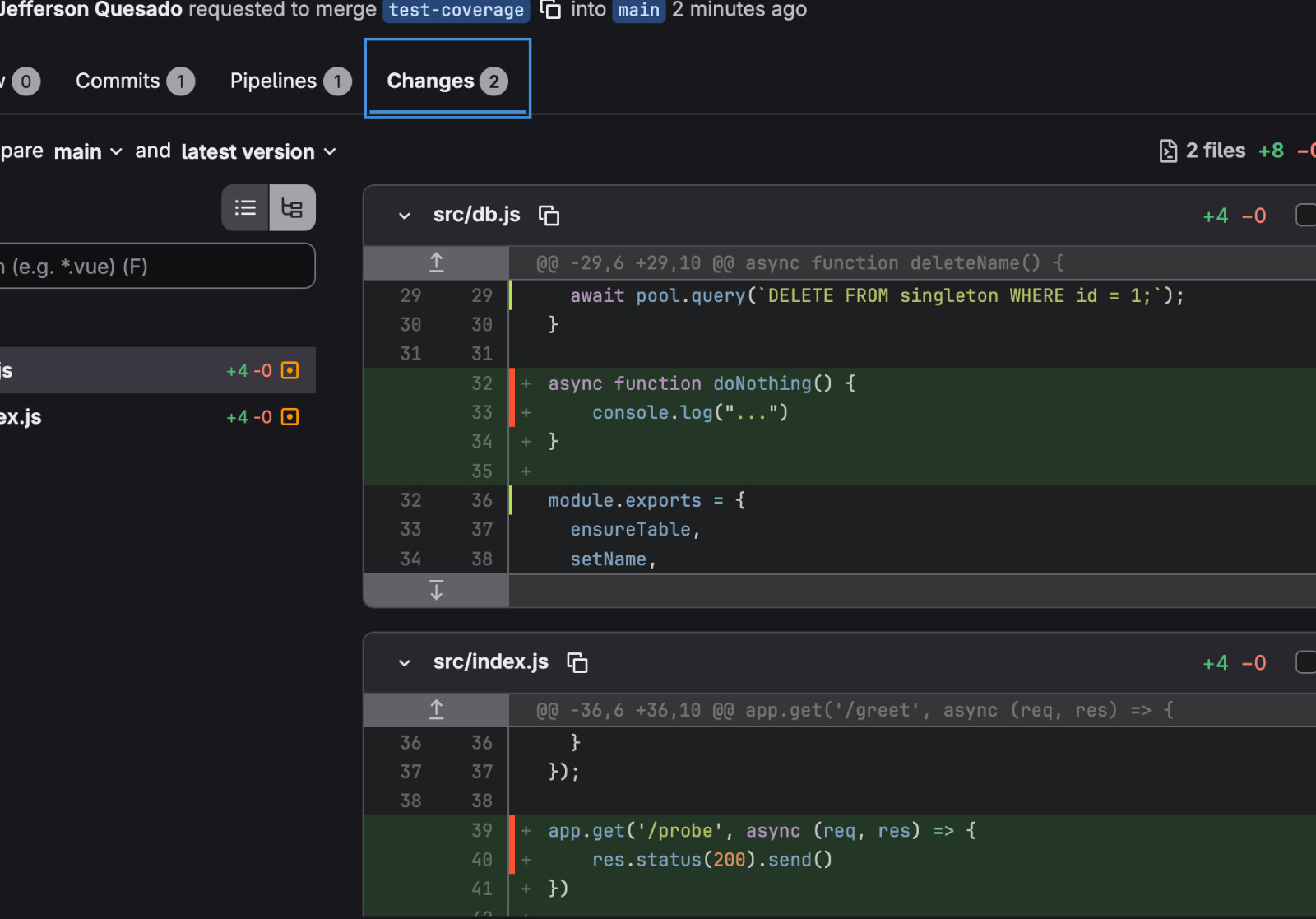
Para esse tipo de relatório, precisei fazer com que o relatório de cobertura do
JEST fosse do tipo cobertura, já que esse tipo de cobertura o gitlab-ci
aceita.
Blog full throttle!!
Uma coisa que me incomodava a bastante tempo na hora de rodar o build do blog era o tempo de espera fazendo o mesmo trabalho repetitivo. Tudo bem que alguma coisa foi otimizada após as análises de tempo específicas feitas no Quebrei o CSS com a publicação anterior, e agora?.
Mas… e se eu não precisar instalar as dependências do Ruby novamente? E se minha imagem estiver boa o suficiente?
Aqui entra a magia! A imagem full-throttle do blog: blog full throtle docker. Esse projeto tem apenas um objetivo: gerar uma imagem com boa parte das dependências já baixadas.
Agora, como conseguir isso? Instalando as coisas tal qual tem no
.gitlab-ci.yaml daqui do blog! Mas para isso seria necessário ter acesso ao
Gemfile e ao Gemfile.lock, não é? Também não tem problema, tem uma API do
GitLab que faz exatamente isso!
A ideia então:
- o job starta manualmente
- primeiro baixamos os arquivos desejados, salvando como artefatos
- inicia o build docker com base na imagem
ruby:3.2-alpine(a imagem usada anteriormente) - instala coisas do sistema (
gcc,g++,bundleretc) - copia o
Gemfilee oGemfile.lock - instala as dependências
- remove o
Gemfilee oGemfile.lock
Assumindo a existência do Gemfile e do Gemfile.lock, o Dockerfile é muito
tranquilo:
FROM ruby:3.2-alpine
WORKDIR /jekyll
ENV BUNDLE_FROZEN=true
RUN apk add gcc g++ make && \
gem install bundler
COPY Gemfile /jekyll/
COPY Gemfile.lock /jekyll/
RUN bundle install && \
rm Gemfile Gemfile.lock
O .gitlab-ci.yaml consiste de 3 estágios:
- start
- fetch dos arquivos
- build do
Dockerfile
O build do Dockerfile é a parte menos sofisticada:
full-throttle-image:
stage: create-image
needs:
- fetch-gemfile
image: docker:24.0.5-cli
services:
- name: docker:24.0.5-dind
alias: docker
before_script:
- echo "$CI_REGISTRY_PASSWORD" | docker login $CI_REGISTRY -u $CI_REGISTRY_USER --password-stdin
script:
- FULL_THROTTLE_IMAGE="$CI_REGISTRY_IMAGE:`date -Idate | tr - .`"
- docker build . -t "$FULL_THROTTLE_IMAGE"
- docker push "$FULL_THROTTLE_IMAGE"
As variáveis
DOCKER_HOSTeDOCKER_TLS_CERTDIRestão registradas globalmente.
A única sofisticação que ele tem é que pega os artefatos do job
fetch-gemfile. O job de start, bem, ele foi feito só para ser uma trava
manual mesmo:
start-pipeline:
image: alpine:3.23
stage: start
when: manual
script:
- echo "Começando a criar a imagem desejada"
O job que faz o fetch dos arquivos, por sua vez, já tem um pouquinho mais de
requinte. Eu precisei do ID do blog para poder bater na API corretamente,
cadastrei na variável COMPUTARIA_BLOG_PROJECT_ID. Além disso, pela
documentação da API de arquivos,
o conteúdo do arquivo estará no campo content, só que estará em base64.
Portanto, a solução foi encadear alguns passos:
curldo arquivo desejadojqpara pegar o campo desejadobase64 -dpara decodificar o arquivo de volta
E, claro, guardar os arquivos como artefatos:
fetch-gemfile:
image: alpine:3.23
stage: fetch-files
needs:
- start-pipeline
before_script:
- apk add curl jq
script:
- >
curl -s -H "Private-token: $CI_JOB_TOKEN" "${CI_API_V4_URL}/projects/${COMPUTARIA_BLOG_PROJECT_ID}/repository/files/Gemfile?ref=HEAD" -o gemfile-dl.json
- jq -r ".content" gemfile-dl.json | base64 -d > Gemfile
- >
curl -s -H "Private-token: $CI_JOB_TOKEN" "${CI_API_V4_URL}/projects/${COMPUTARIA_BLOG_PROJECT_ID}/repository/files/Gemfile.lock?ref=HEAD" -o gemfile-lock-dl.json
- jq -r ".content" gemfile-lock-dl.json | base64 -d > Gemfile.lock
artifacts:
paths:
- "Gemfile"
- "Gemfile.lock"
Eu criei um conjunto de estágios próprios para esse projeto:
stages:
- start
- fetch-files
- create-image
Simplesmente porque achei que esses são os nomes mais semânticos para o que está sendo feito em cada momento.
Usando a imagem
Após fazer o build, eu simplesmente subsituí a imagem base usada no blog:
default:
- image: ruby:3.2-alpine
+ image: registry.gitlab.com/computaria/blog-full-throttle-docker:2026.02.10
Nenhuma outra mudança foi feita, inclusive os apk add continuam no lugar, e
também o bundle install. Manter esses processos de instalação ajuda a, caso
seja necessário mudar algo no container (como instalar, sei lá, jq?), o blog
está pronto para se adaptar e reagir, não ficando preso à imagem
full-throttle.
E, bem, após o primeiro experimento… o tempo de build caiu de 1min45 para 46s, sendo que após o momento que inicia o script o tempo foi 18s. Simplesmente mágico!