Manipulando query string para melhor permitir compartilhar uma página carregada dinamicamente
Interagindo no Bluesky acabei conversando com Moreno Colaiacovo. Após uma troca rápida e amigável, resolvi explorar mais o perfil dele e encontrei o Genomics Daily.
Explorando o Genomics Daily, encontrei o archive. Mas uma coisa me incomodou: eu não conseguia compartilhar a data específica que uma notícia surgiu. Então, pensei: “por que não abrir um PR?”
Estrutura do site
O Genomics Daily é uma página
estática servida pelo GitHub Pages. Seu repositório é
emmecola.github.io. Como um
GitHub Pages clássico, é um SSG Jekyll.
Descobri mexendo nesse projeto que o GitHub pages agora tem a possibilidade de hospedar o resultado de uma GitHub Action:
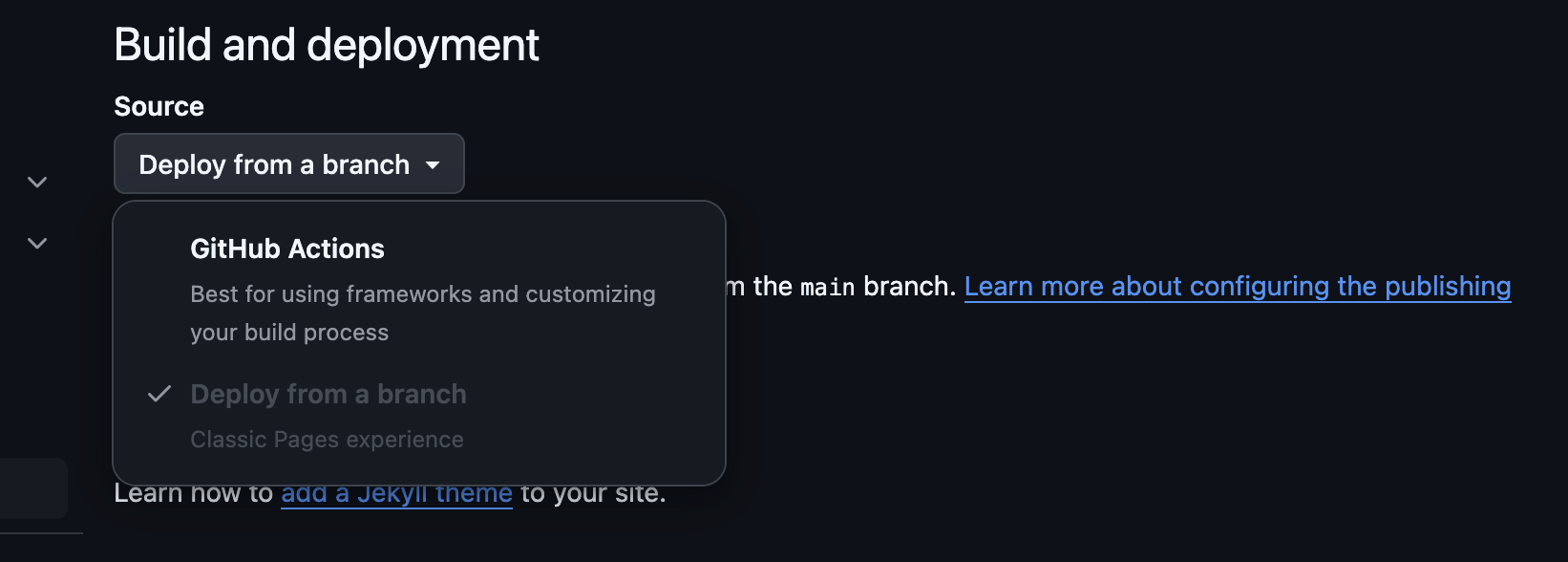
Rodando dois Jekylls em paralelo
Botei para rodar o Genomics Daily em modo padrão. Ou seja: porta 4000. E escrever este post aqui no Computaria sem verificar é… é chato. Então, vamos lá. Corrigir isso.
Para isso, uma pequena olhada no código do Jekyll. E…
achei!
A opção se chama port!
Ok, em segunda olhada eu vi que também tem disponível facilmente na página web da própria documentação das opções do Jekyll. Ok, consegui a informação que eu precisava, os detalhes não importam tanto.
Então, eu poderia simplesmente chamar o bundle exec jekyll s -w -d -p 4001,
mas meu
fluxo atual é com rake,
então vou ficar com ele. Portanto, passar a opção da porta para o rake.
Para isso, usei um padrão:
rule(/^run-[0-9]+$/) do |t|
port = t.name["run-".length() ..]
run_jekyll port: port
end
Eu pego o nome da task e dela a substring após run-. Então passo para a
função run_jekyll com o parâmetro nomeado port:
def run_jekyll(port: nil)
# debugging
puts "port? #{port}"
require "jekyll"
opts = {
'show_drafts' => true,
'watch' => true,
'serving' => true
}
opts['port'] = port unless port.nil?
# mais debugging
puts opts
conf = Jekyll.configuration(opts)
Jekyll::Commands::Build.process conf
Jekyll::Commands::Serve.process conf
end
Essa função foi obtida a partir da task orginial run, que ficou assim:
task :run do |t|
run_jekyll
end
Fazendo isso, temos as APIs:
rake run # vai rodar na porta padrão
rake run-4001 # vai rodar na porta 4001
Bem, isso funciona e funciona bem. Mas o jeito, digamos, mais padrão de passar
parâmetros para o rake é usando chaves. Vamos tentar? Estou seguindo a
documentação.
No primeiro teste, queria simplesmente saber o que acontece se, por acaso, eu
não passar nenhum complemento. Criei uma task chamada run2 só para usar ela
nos testes. O jeito geral dela ficou assim:
task :run2,[:port] do |t, args|
#...
end
Para testar o resultado, mandei imprimir o argumento port e se ele era nulo
ou não:
task :run2,[:port] do |t, args|
puts args.port
puts args.port.nil?
end
Rodei os seguintes comandos e obtive os seguintes resultados no bash:
> rake run2
true
> rake run2[123]
123
false
Mas… minha shell padrão do sistema é zsh. E rodando no zsh tive um comportamento… ligeiramente diferente…
> rake run2[123]
zsh: no matches found: run2[123]
O que isso quer dizer? Que ele tentou fazer alguma expansão da própria shell em
cima de run2[123], enquanto que o bash ficou satisfeito em lidar com isso
como se fosse uma simples string. Para rodar com parâmetros precisar usar de
escapes da própria shell. Seja o basckslash ou botando entre aspas ou
apóstrofos:
> rake run2
true
> rake 'run2[123]'
123
false
> rake "run2[123]"
123
false
> rake run2\[123\]
123
false
Ok, tudo certo. Como a falta do argumento funciona de modo igual ao valor nulo,
vou deixar tudo na task run mesmo, com o parâmetro opcional da porta.
Inclusive esse parâmetro opcional aparece no rake --tasks. De modo
semelhante, alterei também o rake browser para permitir parametrizar a porta
da mesma exata maneira:
task :run,[:port] do |t, args|
require "jekyll"
opts = {
'show_drafts' => true,
'watch' => true,
'serving' => true
}
opts['port'] = args.port unless args.port.nil?
conf = Jekyll.configuration(opts)
Jekyll::Commands::Build.process conf
Jekyll::Commands::Serve.process conf
end
task :browser,[:port] do |t, args|
require 'dotenv/load'
port = unless args.port.nil?
args.port
else
4000
end
sh "open #{"-a #{ENV["BROWSER_NAME"]}" unless ENV["BROWSER_NAME"].nil?} http://localhost:#{port}/blog/"
end
Mudanças na URL
Meu primeiro experimento foi alterar location. Descobri que tem um campo
chamado location.search que é onde moram os query params. Por exemplo, se
abrir uma URL tipo
https://computaria.gitlab.io/blog/about/?status=true,
o valor de location.search será "?status=true". Ok, então posso fazer um
simples location.search = "?a=b", correto? Bem, na verdade, não…
Por que não? Porque isso muda o comportamento atual da página Genomics Daily,
que é carregar o recurso dinamicamente sem haver recarga de página. Portanto,
se eu quiser oferecer alguma alteração para permitir compartilhar a página do
dia escolhida no archive, eu não posso escolher fazer assim. Mas, que outras
opções eu tenho?
Descobri
nesta resposta do StackOverflow
que eu posso brincar com a API de history! Vamos brincar aqui no Computaria
essa API?
Ao clicar, você deve perceber que passou a aparecer na URL um query param com
o valor marmota=1, e ao clicar novamente muda para marmota=2 e sai
incrementando o valor associado à chave marmota para todo e qualquer clique.
A implementação foi assim:
function alteraQueryParam() {
const url = new URL(window.location.href);
if (!window.history) {
alert("Este browser aparenta não ter API de history")
return
}
const paramName = 'marmota'
let x = url.searchParams.get(paramName)
if (!!x) {
x = Number(x) + 1
} else {
x = 1
}
url.searchParams.set(paramName, x);
window.history.pushState(null, '', url.toString());
}
Habilitando o Genomics Daily localmente
Clonei o repositório e a primeira coisa que fiz foi copiar o Rakefile do
Computaria para o meu clone local (sem commitar, claro). E quando dou um
rake run… ele não deu certo! Por quê? Porque ele não encontrava o tal de
minima. Mas onde estava esse minima?
minima é um tema do Jekyll, declarado no
_config.yaml da página do Genomics Daily:
include: [".well-known"]
theme: minima
header_pages:
- README.md
- genomics-daily/index.html
Ok, preciso instalar a gem, e agora? Bem, por via das dúvidas, copia o
Gemfile também e adiciona essa gem lá. Feito isso, bundle update e…
rake funcionou.
Ajuste em links internos
O link original que saía do dia atual para o archive não funciou no meu fork.
Para corrigir isso, sem mudar o comportamento atual, simplesmente transformei o
/genomics-daily/archive/ em URL relativa:
<div>
<a
- href="/genomics-daily/archive/"
+ href="{{ "/genomics-daily/archive/" | relative_url }}"
style="float:right"
title="View the Genomics Daily archive"
aria-label="View the Genomics Daily archive">
Archive
</a>
</div>
Carregando a página
Aqui temos dois desafios: carga inicial e atualizar o query param.
Atualizar o query param
Essa parte é tranquila, já resolvemos logo acima. Agora, toda vida que disparar
o evento que faz a carga do dia do Genomics Daily precisamos atualizar chamar
a função de history para atualizar a URL sem causar recarga da página.
No caso, ele já estava interceptando quando havia uma submissão do formulário, então aproveitei esse trecho:
form.addEventListener('submit', (e) => {
e.preventDefault();
const date = document.getElementById('documentDate').value;
+ if (window.history) {
+ const url = new URL(window.location.href);
+ url.searchParams.set('date', date);
+ window.history.pushState(null, '', url.toString());
+ }
const [year, month, day] = date.split('-');
const formattedDate = `${year.slice(2)}-${month}-${day}`;
fetch(`summary-${formattedDate}.md`)
.then(response => response.text())
.then(data => {
document.getElementById('result').innerHTML = marked.parse(data);
})
.catch(error => console.error('Error loading content:', error));
});
Com isso já temos a possibilidade de ao selecionar uma data poder compartilhar a URL já com a data selecionada. Agora, precisamos botar isso para ser algo útil.
Utilizando ao carregar a página
A primeira coisa que eu queria fazer era ter acesso ao HTML inteiro da página
para poder por um onready no <body>, mas eu não tinha acesso. Seria
necessário mudar no _layout e, sinceramente? Parece complicação demais.
Outra alternativa seria usar o <script defer> (como fiz em
Deixando a pipeline visível para acompanhar deploy do blog),
mas isso implicaria remover a localidade do código JS de dentro do HTML. Então,
qual evento a mais eu consigo detectar? Bem, uma das alternativas (talvez não a
melhor) é interceptar o evento load do objeto window:
<script>
window.addEventListener('load', () => {
console.log('oie')
})
</script>
Apertei F5 e lá estava a mensagem do console. Ok, satisfeito. Enquanto escrevia
este post eu me questionei, “será que não poderia ter usado window.onload?”
<script>
window.onload = () => {
console.log('oie')
})
</script>
E funciona também, magnificamente bem. Nessa situação, quando termina de
carregar aquilo que é necessário, podemos disparar a chamada para buscar as
novas informações. Basicamente é extrair a data do query param date e,
estando ele presente, chamar a mesma função que tem no evento de submissão do
form. Para isso, primeiro extraí a função de carregamento de conteúdo do evento
de submissão:
function loadSummary(date) {
const [year, month, day] = date.split('-');
const formattedDate = `${year.slice(2)}-${month}-${day}`;
fetch(`summary-${formattedDate}.md`)
.then(response => response.text())
.then(data => {
document.getElementById('result').innerHTML = marked.parse(data);
})
.catch(error => console.error('Error loading content:', error));
}
form.addEventListener('submit', (e) => {
e.preventDefault();
const date = document.getElementById('documentDate').value;
if (window.history) {
const url = new URL(window.location.href);
url.searchParams.set('date', date);
window.history.pushState(null, '', url.toString());
}
loadSummary(date)
});
Ficou no handler do form apenas a parte específica de resgatar o valor date e
de empurrar na URL o query param. De resto, fica na função de carregar o
conteúdo, loadSummary. E no carregamento:
window.onload = () => {
const url = new URL(window.location.href);
if (url.searchParams.get("date")) {
const queryDate = url.searchParams.get("date")
document.getElementById('documentDate').value = queryDate
loadSummary(queryDate)
}
}
Pronto, aqui eu estou carregando o conteúdo com loadSummary do mesmo jeito,
mas também aproveitei e para evitar qualquer confusão coloquei o valor do
componente do formulário para o valor correto.
Fiz alguns testes colocando a atribuição de função window.onload dentro de
um setTimeout, e o resultado mostrou que o load não é disparado:
setTimeout(() => {
window.onload = () => {
const url = new URL(window.location.href);
if (url.searchParams.get("date")) {
const queryDate = url.searchParams.get("date")
document.getElementById('documentDate').value = queryDate
loadSummary(queryDate)
}
}
}, 0)
Mesmo com o intervalor de espera em 0ms. Para contornar isso, resolvi perguntar
para o documento se ele já estava no estado completed. Se sim, chamava a
função de carregamento, caso contrário botava o listener de evento.
setTimeout(() => {
function firstLoad() {
const url = new URL(window.location.href);
if (url.searchParams.get("date")) {
const queryDate = url.searchParams.get("date")
document.getElementById('documentDate').value = queryDate
loadSummary(queryDate)
}
}
if (document.readyState === 'complete') {
console.log("completed") // debug
firstLoad();
} else {
console.log("evento") // debug
window.onload = firstLoad
}
}, 0)
E passou pelo debugging de completed, não evento. Ok, feliz. E sem a
gambiarra do setTimeout passou pelo outro ramo, perfeito.